pre
- MMO游戏服务器,主语言C++11,辅助语言Lua
- 优化点:
- 运行时 cpu 占用
- 启动速度
- 总结改动:除了 lua 版本的变更其他都是很简单的改动项;实际给一个已经上线项目做优化时改动点并不多,都是很小的细节,一段逻辑除非命中的特别多并且有明显的性能问题才会被单扣出来整理逻辑着看
- 引用、拷贝语法造成的差异
- 遍历没有用引用方式
- 返回值不是引用的或者拿值类型接收了引用类型的返回值
- 容器栈、指针(lazy construct)的差异
- 连续容器(std::vector)reserve 的影响
- RVO/NRVO 的优化
- 循环的优化
- 更现代的内存分配器
- 引用、拷贝语法造成的差异
- 这些就都是些代码的习惯….而且刚来的时候就写过[优化Tips]的文章;然而一年过去了该有的问题还都有,注释也还不加….只是能跑的代码
- 不注意细节的C++肯定是比Java还慢的(Java里除了基础类型全是引用)
lua 5.3.X 版本 table 遍历问题
直接看结论:
- lua 5.3.X 版本中 hashint (64bit) 的实现有问题,5.4.X 版本修改问题,速度提升很多
- via: https://www.cnblogs.com/coding-my-life/p/16990992.html
pre
压测发现 lua malloc 占用比较高
裸的程序考虑载入 tcmalloc 试试
然后看到占用较高的是
1
2+ 26.50% 25.29% XXXX XXXX [.] luaH_next
+ 13.47% 12.18% XXXX XXXX [.] luaV_equalobj查资料知道:
luaH_next是遍历 hash table 的luaV_equalobj是比较两个对象是否相等
起初是怀疑lua代码实现上有太多
for one pairs(table) do这种,但是程序载入的 lua 量太大了,排查遍历热点太困难了机器上装了lua相关的东西,就想先试试多大的量会引起性能热点
1
2
3
4
5
6
7test_table = {}
for i = 1, 200000 do
test_table[i] = i
end
for one in pairs(test_table) do
end实际测试下来,20W的量级时间消耗也几乎可以忽略(20W是实际业务上最大的一块对象,全服怪物对象,实际没有接口可以拿到全服怪物对象列表)
又怀疑是 lua 有循环套循环的情况,一样陷入僵局,代码量很大想排查这个太麻烦了
转到
luaV_equalobj的热点问题上如上查到相关问题,修改测试代码
test_table[i] = i->test_table[i << 32] = i复现问题,替换lua版本重新测试
luaH_next热点仍在luaV_equalobj已经消失
std::set 构造问题
pre
- 前面压测 500 人在线已经基本稳定,被要求先处理启动问题
先用 timer_cost 分段打印启动耗时
1 | class timer_cost { |
地图实例化时基于配置数据拷贝时间耗时很大
因为地图很大 1000 * 1000 很常见,而最初阻挡信息是标记在一个 cell 上的,也就是每张地图都拷贝了 大小 = 1000 * 1000 cell 的容器
怀疑是 vector 拷贝写法问题,压测了几种写法差异
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
static const int64_t N = 1000000;
static const int64_t M = N - 1;
static const std::vector<int64_t> vec = [](){
std::vector<int64_t> vec;
vec.resize(N);
for (int i = 0; i < N; i++) {
vec[i] = i;
}
return vec;
}();
void func1(benchmark::State& state) {
for (auto _ : state) {
std::vector<int64_t> dst;
dst.reserve(M);
std::copy(vec.begin(), vec.begin() + M, dst.begin());
benchmark::DoNotOptimize(dst);
}
}
BENCHMARK(func1);
void func2(benchmark::State& state) {
for (auto _ : state) {
std::vector<int64_t> dst;
dst.resize(M);
memcpy(&dst[0], &vec[0], M * sizeof(int64_t));
benchmark::DoNotOptimize(dst);
}
}
BENCHMARK(func2);
void func3(benchmark::State& state) {
for (auto _ : state) {
std::vector<int64_t> dst(vec);
dst.reserve(M);
benchmark::DoNotOptimize(dst);
}
}
BENCHMARK(func3);
void func4(benchmark::State& state) {
for (auto _ : state) {
std::vector<int64_t> dst(vec.begin(), vec.end());
benchmark::DoNotOptimize(dst);
}
}
BENCHMARK(func4);
void func5(benchmark::State& state) {
for (auto _ : state) {
std::vector<int64_t> dst(M);
std::copy(vec.begin(), vec.begin() + M, dst.begin());
benchmark::DoNotOptimize(dst);
}
}
BENCHMARK(func5);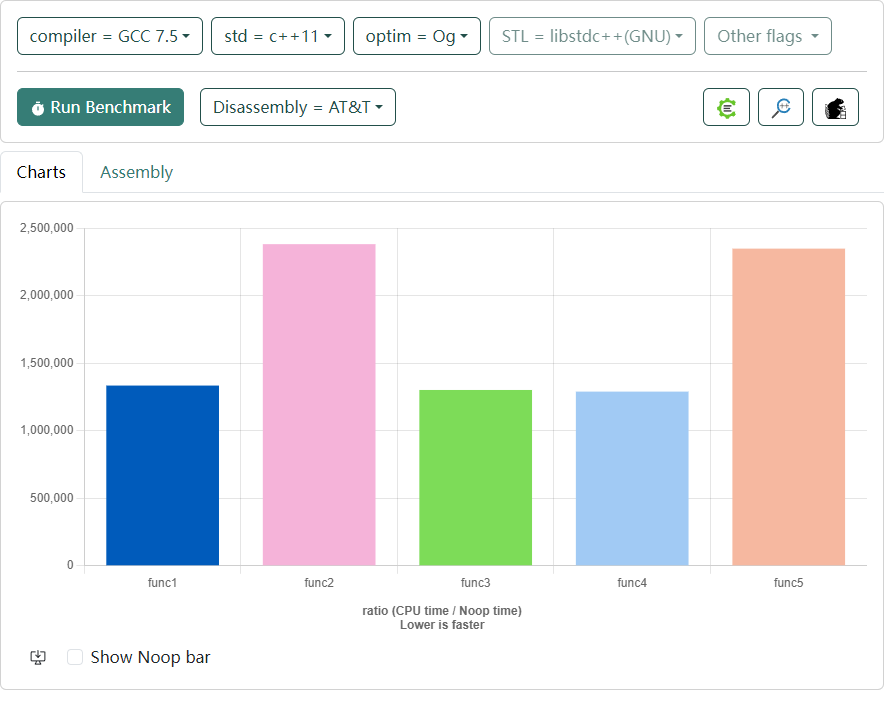
程序也用了正确的方式
加中断挂 perf 工具
1 | std::getchar(); |
- 看到耗时点是 cell 结构里一个
std::unique_ptr<std::set<uint64_t>>的数据成员….容器成本很高 - 这个在从源数据做拷贝的时候是不需要拷贝的,注释掉之后性能提升
std::future wait
https://stackoverflow.com/questions/10890242/get-the-status-of-a-stdfuture?rq=4
实际测试 c++11 版本 没有设置的 future:
f.wait_until(chrono::system_clock::time_point::min());快近300倍;MSVC平台并不明显这里遗留了一个问题,异步任务完成后的同步信号;
- 例如使用
std::async,返回std::future,如果持有这个返回值wait_for/wait_until,用来等待的线程仍然是阻塞的 - 前面做测试是丢了一个容器到线程任务里,完成任务存入容器,主线程消费容器内容,但是这个容器是需要加锁的
- 最好的方式是协程的写法,无奈公司技术比较老
- 例如使用
内存分配器 TODO
测试中发现msvc/gcc下内存实际占用差异很大(windows 7GB,linux 3.5GB)
代码没有注意过内存对齐的问题,基础类型、容器、对象都是随意放的,这些改起来量太大了
1
2
3
4
5
6
7
8
9
10
11struct x {
int _int;
float _float;
};
struct xx : public x {
std::vector<int> _vector_int
}
sizeof(x) // msvc: 8, gcc: 8
sizeof(xx) // msvc: 40, gcc: 32测试过程中也发现 msvc 的内存分配速度相比更慢(gcc下用了tcmalloc)
msvc 取 gperftools 里的 tcmalloc_minimal 做了替换,反而拖慢了速度,内存占用更小了(约 4GB),但是当前速度更重要
tcmalloc windows: https://github.com/gperftools/gperftools/blob/master/README_windows.txt
mimalloc 微软开发的内存分配器,发现性能也没有更好
mimalloc windows: https://github.com/microsoft/mimalloc