Optimizing Tips
某次给内部同事的分享
前提:先编写正确的代码,再优化
- 先完成需求,实现业务内容,先让程序跑起来
- 可能在做单元测试的过程中就可以看出哪个函数被频繁调用了,哪个逻辑做多了遍历或者搜索
- 然后分析以发现瓶颈(热点),并消除瓶颈(热点)
- 这样得到的成效往往是最直接和明确的
- 优化的顺序:要么先消除最大的那个热点,要么先消除一眼就可以改掉的那个热点
- 通常到最后是需要靠算法上的优化消除那个遗留下来的最麻烦的点,做这件事情的时候如果拿不准,就先多做粒度比较小的压测,找到适合的方式
优化核心:
- 缓存命中、复用
- L 级缓存的命中
- 复用避免拷贝
- 原子单位
- 避免时间片跳出
- 汇编指令重排
- 重排指令
- 跳转、压栈、出栈的优化
- IO异步
- 与其他设备级(网卡、磁盘等)交互的异步化
循环调用:
1 | for each (auto& one : range(1, 100)) { |
1 | caller() { |
↓↓↓
函数调用需要两次跳转,还会有堆栈内存操作(参数/返回值/临时变量
压栈出栈)优先使用迭代循环(相对递归来说),由于函数调用的栈空间是在出函数体才释放的,递归层级太深会导致栈溢出
可以使用(短的)内联函数消除函数跳转问题
循环内避免动态分配内存(new/malloc)对于所有内存模型
ptmalloc/tcmalloc/jmalloc
这个动作很可能是要加锁的,循环本身是个cpu密集的行为,想象每次循环都被lock一下会怎么样?可跳出的循环,尽量提早跳出,break/return
遍历:
1 | int array[__line][__row] = {{...}, {...} ...}; |
1 | for (unsigned i : __line) { |
1 | for (unsigned j : __row) { |
- ↓↓↓
- 数组的空间是连续的,也就是内存是连续的,顺序的访问内存和乱序(随机、跳转)访问内存性能差别很大
array[i][j]和array[i][j+1]相邻array[i][j]和array[i+1][j]很远
1 | const std::vector<...>& get_all() const { |
1 | const std::vector<...>& get_all_filter(std::function<bool(...)>&& checker) const { |
- ↓↓↓
- 试想为什么有些程序会定义 attr 的宏来限制对数据成员的操作只有 get/set
判断:
- 如果不是要检查每种条件,把if… else if… else…
换成switch语句,编译器对swich更容易做优化,特别是switch常量那种 - if 首先判断经常发生的情况
1 | if (men) { |
提前退出:
- 循环/遍历/迭代
很多时候都是可以提前退出的,很多逻辑在纸上写(画)和代码写是两个思路
尽量少的参数数量:
- 简单类型的参数,如果数量足够少,尺寸足够小,会被压到寄存器里面,特别是外层有循环迭代的情况,寄存器访问比内存访问快的多
- 如果是仅函数内部使用的参数,使用std::move(),
- 如果是其他参数,使用 const xx& (不可被改变), xx& (可被改变)
尽量少的局部变量:
- (同参数解释)
- 局部变量如果是在一个空间内使用的 {}, 在空间内声明,比如 if { int a = 0; }
- 局部变量一样,声明必带初始化(不要相信编译器对常规变量的默认初始化)
尽量简单的返回值:(std::move语义)
尽量使用引用传递参数/返回值:(对于成员变量)
- 作为参数,想不到有什么场景是需要以值传递的…
- 返回值需要关注是否在函数退出会被释放(栈空间),如果是可以用 static
修饰 - stl clear 语义比 construct 语义快很多
- swap 语义一般是用新对象覆盖,不同的方式开销不一样,再讨论…
- 如果知道容器需要的容量,提前 reserve,特别是 vector
这种容器,所以新标准有了 array
容器
- 定长容器虽然有限制,但是对内存更友好;
如果是可以预估数量级的数据,优先使用定长容器或者reserve
(https://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html) - std::unordered_map 相比 std::map
时间复杂度更低,但是是在较大的数据量上;较小的数据量,较复杂的key(长std::string)带来的hash消耗会导致std::unordered_map不如std::map更快 - 同理 std::unordered_set std::set
- 嵌套的容器在语义和理解上都更不友好,添加 make_key 方法 ->
std::string, std::tuple, user-define struct - 如果 make_key 需要
hash,尽量用主流的hash算法,注意碰撞和算法本身的消耗 - 一般情况 user-define struct 都可以被 std::tuple
替代,虽然缺少了struct明确的语义,但是std::tuple的可展开性更容易写通用的hash函数 - see:
https://www.boost.org/doc/libs/1_35_0/doc/html/boost/hash_combine_id241013.html
轻量化调用链路: (这只是一个更清楚的感受)
1 | call_a(...); |
1 | function call_b(...) { |
虚函数:
- 虚函数比普通函数调用的代价高很多… 这个是必要的么? 参考 CRTP
- 虚函数相比普通函数调用的代价从cpu crycle 来看并没有高多少;只是多了一次虚表查询,但是这个查询的代价可以被认为是固定的(虚函数表指针(vptr)则存放在类对象最前面的位置,即对象内存布局的最前面)
- 但虚函数的问题是:
- 虚函数被滥用了,看到很多同学做设计时把继承于基类对象的所有方法都定义为虚函数(为了使用时只用基类类型就可以),这会导致虚函数表的膨胀,增加内存消耗,增加内存访问的消耗
- 虚函数不能像普通函数一样在编译期被优化 (inline/constexpr)
1 | // crtp 不是灵丹妙药,模板的引入导致引入了更多类型;这只是反virtual的的宣誓。(当然他的性能确实更好) |
明确类型:
- 数据处理上尽量明确类型,避免 cast
- 不同数据类型所需要的空间是不一样的,甚至缓存他们的寄存器都不一样(int/float)
- 每次cast都相当于要检查寄存器空间,甚至切换寄存器
- see: https://zh.wikipedia.org/wiki/%E5%AF%84%E5%AD%98%E5%99%A8
构造函数:
- 新标准有了默认初始化方式
- 额外需要初始化的尽量写在初始化列表区,而不是构造的函数体
- 不要相信默认构造函数
- 加上右值构造,可能今后这个才更常被调用到
1 | class abc { |
初始化:
- 对象/结构的声明直接做初始化
- abc abc_(1);
- abc abc_; abc_ = …
- 想要再编译器检查这个写法:explicit
- stl 的初始化,参考 std::initializer_list
析构函数:
- 构造析构是继承 override
上基类和派生类命名不同的函数(其实他们的函数一个是没有函数名,一个是~) - 派生类析构后会调用基类的析构,但是如果基类没有虚析构,指向基类的对象就认为需要释放的只是他自己(虚表找不到析构)
- 感谢编译器在基类virtual修饰的函数上默认派生类是可以不写 virtual
override 的,但也造成了不清不楚的问题 - 如果就是不想要虚析构,用 final 修饰你的结构
数据运算
数据运算尽量避免三元运算符
1
2
3a = a + 1; // 如果可以,用 += 替换
a += 1; // -=, *=, /= 同理
a = bool_ ? x : y; // 三元运算符会产生额外的变量- 上面乍一看只是简单数据类型,一些新的编译器会做优化,但是如果a的类型是一个
struct… 比如坐标点(x, y, z) - += 相比 + 可以减少一次临时对象的分配
- 同理 ++a, a++
- 上面乍一看只是简单数据类型,一些新的编译器会做优化,但是如果a的类型是一个
数据类型:
- 数据在内存里操作的最小单位是4字节(int),int8, int16,
如果涉及计算,会被用4字节空间计算,然后再转化成对应类型;所以才有代码用
8, 16 类型只做常量声明
rename:
- 一定有必要 rename 数据类型么?如果需要,语言层面 using
更好看(相比类外的 typedef,甚至 #define)
1 | class string_view { |
auto delete:
如果 std::shared_ptr<> 不是所有人都接受的新内容(被遗忘的
std::weak_ptr<>)std::unique_ptr<>
一定可以让你的代码更干净,毕竟更多的情况不是内存申请出来就可以继续使用的1
2
3
4
5std::unique_ptr<abc> abc_(new abc());
if (!abc_->testOK(...) || !testOK(abc_)) {
...
// delete abc;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14template<typename _Ty>
std::shared_ptr<_Ty> make_shared_array(size_t size) {
return std::shared_ptr<_Ty>(new _Ty[size], std::default_delete<_Ty[]>());
}
template<typename _Ty, class... Args>
inline typename std::enable_if<!std::is_array<_Ty>::value, std::unique_ptr<_Ty>>::type make_unique(Args&&... args) {
return std::unique_ptr<_Ty>(new _Ty(std::forward<Args>(args)...));
}
template<typename _Ty>
inline typename std::enable_if<std::is_array<_Ty>::value && std::extent<_Ty>::value == 0, std::unique_ptr<_Ty>>::type
make_unique(size_t size) {
using _reTy = typename std::remove::extent<_Ty>::type;
return std::unique_ptr<_Ty>(new _reTy[size]());
}
讨论:
- C++的引用类型是一种选择;而其他语言 java/c#
引用是唯一的选择(不要争执span,毕竟是会在编译期被提醒的),为什么? - 多态有静多态, 动多态;为什么?
- typedef 初衷应该是为了明确语义,隐藏模板的侵入;不要让他污染了你的程序
- auto 并不能解析出 & ,只是 auto x = -> const type_x& {…};
是一个拷贝 - 在纸上画结构,标记逻辑跳出点(纸上的逻辑比程序更清楚)
- 在纸上列出已有的内容,和想求得的结果(纸上的算法优化比程序更直接)
….
1 | - 避免繁复的设计。(架构设计是横向的,内容(实现)设计是纵向的,期望最终得到的是一个近似正方形) |
附录:
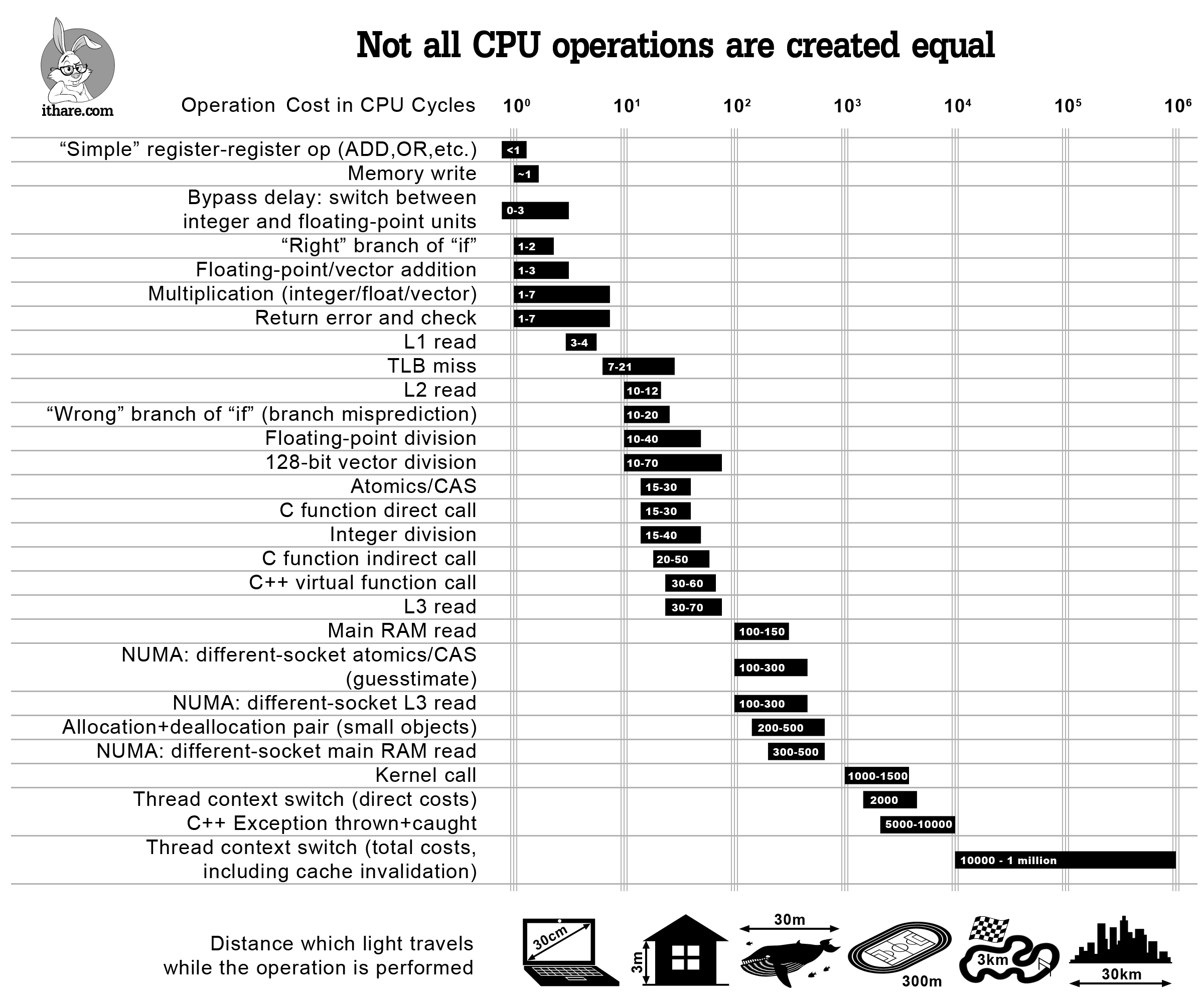
系统的各种延时:
| 事件 | 延迟 | 相对事件比例 |
|---|---|---|
| 1个CPU周期 | 0.3 ns | 1 s |
| L1 缓存访问 | 0.9 ns | 3 s |
| L2 缓存访问 | 2.8 ns | 9 s |
| L3 缓存访问 | 12.9 ns | 43 s |
| 主存访问(从CPU访问DRAM) | 120 ns | 6 分 |
| 固态硬盘I/O(闪存) | 50-150 us | 2-6 天 |
| 旋转磁盘I/O | 1-10 ms | 1-12 月 |
| 互联网:从旧金山到纽约 | 40 ms | 4 年 |
| 互联网:从旧金山到英国 | 81 ms | 8 年 |
| 互联网:从旧金山到澳大利亚 | 183 ms | 19 年 |
| TCP 包重传 | 1-3 s | 105-317 年 |
| OS 虚拟化系统重启 | 4 s | 423 年 |
| SCSI 命令超时 | 30 s | 3 千年 |
| 硬件虚拟化系统重启 | 40 s | 4 千年 |
| 物理系统重启 | 5 m | 32 千年 |
物理距离->网速基准值推算公式:
- 光速:299792458 m/s -> 300000 km/s
- 光纤是经物理介质的,理论值会比光经空气慢;一般简化用 200000 km/s
为参考 - eg.
新加坡 - 美弗吉尼亚物理距离: 15000 km;单程时间:15000 / 200000
* 1000 = 75 ms;RTT(ping)约 150 ms
术语:
IOPS:
每秒发生的输入/输出操作的次数,是数据传说的一个对量方法。对于磁盘的读写,IOPS
指的是每秒读和写的次数。吞吐量:
评价工作执行的速率,尤其是在数据传输方面,这个属于用于描述数据传输速度(字节/秒或者比特/秒)。再某些情况下(如数据库),吞吐量指的是操作的速度(每秒操作数或每秒业务数)相应时间:
一次操作完成的时间。包括用于等待和服务的时间,也包括用来返回结果的时间。延时:
延时是描述操作里用来等待服务的时间。再某些情况下,它可以指的是整个操作时间,等同于响应时间。使用率:
对于服务所请求的资源,使用率描述再所给定的时间区间内资源的繁忙程度。对于存储资源来说,使用率指的就是所消耗的存储容量(例如,内存使用率)。饱和度:指的是某一资源无法满足服务的排队工作量。瓶颈:
在系统性能里,瓶颈指的是限制系统性能的那个资源。分辨和移除系统瓶颈是系统性能的一项重要工作。工作负载:
系统的输入或者是对系统所时间的负载叫做工作负载。对于数据库来说,工作负载就是客户端发出的数据库请求和命令。缓存:
用于复制或者缓冲一定量数据的高速存储区域,目的是为了避免对较慢的存储层级的直接访问,从而提高性能。出于经济考虑,缓存区的容量要比更慢以及的存储容量要小。
目标
延时:低应用响应时间吞吐量:高应用程序操作率或者数据传输率资源使用率:对于给定应用程序工作负载,高效的使用资源
大O标记法
| 标记法 | 举例 |
|---|---|
| O(1) | 布尔判断 |
| O(logn) | 顺序队列的二分搜索 |
| O(n) | 链表的线性搜索 |
| O(nlogn) | 快速排序(一般情况) |
| O(n^2) | 冒泡排序(一般情况) |
| O(2^n) | 分解质因数;指数增长 |
| O(n!) | 旅行商人问题的穷举法 |
参考