pre
- 我是个游戏服务端开发。刚出校门就进入了游戏行业,一直觉得没有学满和对不熟悉行业谨小的性格让自己困在这个行业。
- 过往的主要使用的语言是c++,也有两款游戏使用java。重要的节点是九城、盛大、网易,都很深刻。
- 一直在一线工作,最开始的做业务,到独立负责模块,再到后来做架构、设计,现在做重构,一直都在写代码
- 没有结婚、很少的恋爱经历,过往大部分时间都在工作里,近几年才坚决的想逃避996,也更多的自怨自艾。
- 我喜欢开发游戏这件事情,是不是是喜欢的游戏倒还好,我不喜欢当前环境做游戏的这帮人;可谨慎的性格随着年龄上涨越来越严重,也不敢说浪费金钱、健康去押宝理想;在悖论里
- 也是近几年,开始在git上整理记录一些东西,上传一些代码片段。
- 上述没有太多意义,但觉得出现在这里并不突兀,在时间、荷尔蒙溜走的重复里,想逃掉。
- 下面是一些经验的备忘、认为,毕竟很多知识系统都很庞大,关联、影响,记录的完整、正确比简单逐条的备忘、经验复杂的多,轻松一点
自己 · 羡慕新一代有更好的环境资源
- 开这么个tag,今天看综艺,2个小时看了6期,只看了傻白的主唱和蒲羽,反复听蒲羽雾也至的送别(脑补原词部分更清澈的慢一点更上头
- 当前公司是内外网隔离的两台办公机器,一直没觉得会融入团队或者想要融入团队就任性的根据工作需要做自己的事情,团队里只给一个小朋友分享了博客的链接,像蒲羽说的,我羡慕小朋友经历的学生时代有比我当时好太多的环境,上大学之前基本只有高中在网吧摸过电脑打游戏
- 当前工作上想实现的东西会有私心的先在外网搭个框架再挪到内网用,可是最近做的时间基类不想麻烦套过去了,没人看,没人用,可能之后的也不会了;也想到自己不是理想中有开源精神的人;需要对手或者观众,即使做的东西是个很应用层的东西
- 蒲羽 送别.雾也到达世界 太好了,现场可能会止不住流眼泪,上次是万青现场,秦皇岛,忍着不被看到,旁边是喜欢的女生
- 我一直认为技术应该是精致的,当前觉得这种想法不太对,或者说因为太过完美主义不太对;毕竟一直工作在应用层,需求导向
- 追求新的技术不是完全是精致的样子,更多是相信技术的演化应该可以让在应用层的我们工作的更轻松,不过当下所处的环境真实发生的和这个理解是相反的,被引入的新的问题被认为是新的技术导致的,限制使用比指导使用轻松的多;
- 我个人的认识,基础知识是很重要的,计算机于我已经是个复杂的体系,需要严密的逻辑,这些支撑我发挥创造、基于开源的超越,我是个工匠,想轻松应对赚钱这件事情,有时间和空间看的更多
- 这是个应该被反思的问题,计算机没有宇宙的探索浪漫,可对应用者一样是有想象、创造的学科,而且基于经验和实践,应该能让我们更轻松构建上层世界
- 经验更多是试错积累的,通过别人的文档看别人得到的经验或者自己积累的经验;可是如果所处不被认为想要成为、构建一个新时代,试错往往不会被接受
- 遗憾还没有参与到过理想的环境,也还没有能力、勇气、机会构建理想环境,被推着走,只是希望自己去想、尝试、记录更多东西,如果有机会有更多准备,虽然这个过程可能进度很慢
语言 · 箱子里的工具总是不够用,但箱子里拿出来的应该用的趁手
- 我自己的主语言是C++,因为做了不少项目,未来的C++也值得期待
- 也用Java做过2款休闲游戏,当时主要的考虑是团队技术栈,选型的时候综合考虑团队是否能cover住语言、中间件、组件等,在出问题的时候可以解决掉问题是必须的
- 游戏停服一次丢一半玩家的
常识让 C++/go + lua 的组合变得流行,不过做过无状态的服务之后觉得当前的手游如果不是强mmo的那种样子,战斗服以外的服务使用无状态方式更合适 - 在处理简单(偏向解析类)工作的时候,以前最多考虑的是用shell bash,常见的日志解析还是一行shell最简单,其他稍复杂的会选择用python,例如之前用python处理excel配置数据->定制的json
- 一些场景下也选择用 node.js,一些并发场景,例如解析代码文件生成markdown的接口文档
- 除了GC,Java和C++一个很大的区别是反射,当然这算是个功能
设计 · 追求精致,接受不完美
进程、服务
网络
- tcp 相比 udp(rudp)使用重度的多
- 游戏更多是REQ/ACK模型,有序的一来一回,使用任何 rudp 都建议考虑单条消息payload的大小,尽量不要超过 1kbytes(1KB) 或者尽量更小,不然因为丢包造成一条消息总是收不完整造成的用户体验会很差;
- kcp:原理、部分测试(我一直认为网上的测试覆盖并不完整)比TCP更快,但没有用拨测的方式覆盖时间、地区测量之前,我都对他持谨慎态度
- 网络拥挤的时候,运营商会选择先丢弃udp包
- BBR 是很有必要做尝试的选择,之前测试过BBR比CUBIC在弱网环境处理包的能力高很多,而且BBR是只在服务端开启就可以得到明显的提升
- 对于HTTP的协议,之前上过cloudflare的代理,IOS在目标地址支持QUIC的情况下会选择HTTP3的通讯方式,虽然还没有实际使用过QUIC,不过当前看也是未来打有可能更多应用的方向
- rpc
- todo: 超时: 服务间通讯的小概率网络问题
数据、对象
对象模型
- 相比近些年热度很高的ecs模型,我更习惯继承链的方式,可能对我来说继承链是更严格的样子
- 功能上多继承、数据成员方式上如果是 java 更常用多继承,c++ 倒没有特别的倾向;更多的是如果这个东西很小又想要独立出来会使用多继承,相反如果很复杂,有较多的数据成员的模块,会倾向作为对象的数据成员使用
数据处理
- todo: 等幂性:
- todo: 乐观锁:
- C11 基础上越来越多的 non-lock, less-lock 内容(std::atomic内存屏障基础上实现),但我还不是个有足够经验、测试用例去实现、验证一个无锁的功能,所以还是习惯用这种方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class non_lock final {
public:
void lock() {}
void unlock() {}
};
template<typename _Lock = non_lock>
class entity_pool {
// anything....
};
entity_pool new_handle() {
return entity_pool<non_lock>::instance().new_handle(ptr);
}
entity_pool new_handle_mt() {
return entity_pool<std::mutex>::instance().new_handle(ptr);
}
容器
- 容器是离不开的东西
- std::vector 基本是第一选择
- 指针还是栈对象?因为vector是连续的内存空间,空间不够会开辟新的空间,把老的内容拷贝到新的空间,拷贝对于指针来说只是8字节,栈对象基本都更大,但是习惯上还是更常使用栈对象方式,用reserve/resize避免拷贝的情况
- reserve: 如果是常驻容器,会动态增长并且不能确定增长频次、上限的情况下可以不做这个,用系统默认的2倍方式;因为是常驻的,认为运行一段时间之后基本不会在有重新开辟空间的情况。特别在意内存占用除外;或者考虑选择 std::list/deque/queue;如果是临时的,尽量做reserve(虽然经常遗漏)
- resize: 明确长度的时候使用,或者使用c++11的 std::array
- std::list 一般在动态缓存场景使用,比如lru_cache
- std::queue/deque 明确一端插入一端取出的场景,比如thread_pool’s task
- std::stack 明确先进后出的场景,比如依次打开界面,而后以后打开的界面先关闭的顺序关闭界面
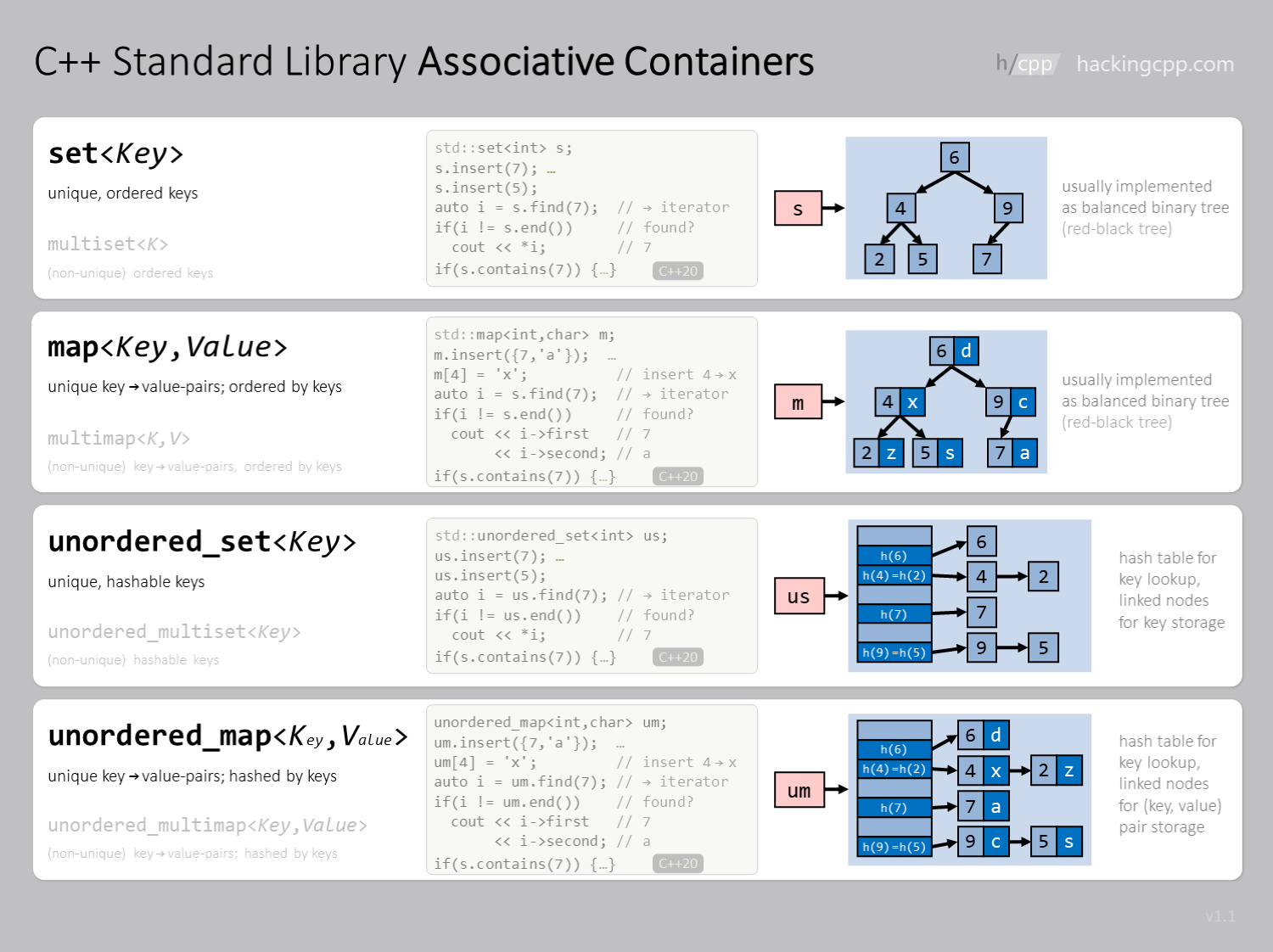
- std::set/unordered_set 数据有唯一性的,unordered比non-unordered占用更多的空间,不在意这个占用优先选择 unordered_set,忽略hash本身的消耗
- std::map/unordered_map 键值对
- struct hash 实现上优先选择 std::hash
- multi 的容器很少用~
- 一些不错的图片:
- emplace/push
- 写法上:
1
2
3
4
5
6
7
8
9
10
11
12
13struct move_test {
std::string _non_used = "1";
int _number = 2;
move_test(std::string&&, int n) : _number(n) {
std::cout << "construct :" << _number << std::endl;
}
};
// test
std::vector<move_test> vec;
vec.push_back({ "10", 1 });
vec.emplace_back("10", 2);
- 写法上:
- move/copy constructor: https://stackoverflow.com/questions/64378721/what-is-the-difference-between-the-copy-constructor-and-move-constructor-in-c



存储
- 这里一般是指存储玩家数据
- 游戏回放数据一般不会有很严格的实时要求,但会有被广播观看需求,认为以文件形式存储以方便同步到cdn更重要
- 抛弃掉传统架构的 db_server, 我更倾向的组合是 redis + mongodb,对应无状态的架构方式
- mysql/mongodb, redis, leveldb 这些是过往用到比较多也很有代表性的三种数据存储(缓存);
- mysql 传统的、关系型
- 游戏更常靠一个玩家一行数据,数据块序列化后存储在 blob 里面,很少会用到事务相关的东西
- 依赖 binlog 的时间点回档也是选择 mysql 一个重要的选项
- mongodb 集群式的、非关系型
- 当时使用 mongodb 有语言(java)的关系
- mongodb 的 bson 和 json 格式基本一致,数据展示上比 blob 方便太多
- nosql 的特性也使得扩展变得很容易
- 如果选择的是云商的PaSS服务,没有很特别的集群需求,standalone 永远是首选
- 集群的 mongo 因为 mongoS、mongoC 的方式,效率比单点低
- 集群需要考虑清楚使用什么样的分片规则
- 当然价钱也是很重要的一个方面
- redis 缓存(集群、单点)
- 集群:一般作为数据存储,游戏是个读多写少的场景(MMO常见的做法是使用进程的内存),redis在架构图上一般被画在Hard_DB之前,也表述了redis主要作用是减轻DB读取的压力
- 单点:在成本考虑上也经常被用于数据存储,之前就有游戏前期考虑并发压力使用集群方式,后期数据下滑换成了单点
- 单点:还有场景是需要使用lua完成一些复杂、原子的操作
- 读取策略:先从redis读,读不到从DB读,并写入redis
- 写入策略:先写DB,成功后更新redis,失败删除redis数据(数据一致性)
- expire:原则上任何数据都需要设置过期时间(一般2小时),游戏这种数据由热数据变成冷数据基本是玩家的行为;这里对于访问特别频繁、并发量可能很大的数据,过期时间需要加随机值,避免同时过期造成的雪崩
- levelDB:需要本地存储场景很合适,也是我的首选
- mysql、mongodb 在数据上用序列化的名词解释,mysql有idl类似protobuf,mongodb没有idl类似json,虽然mongodb会有更多的带宽消耗,不过一般在部署上都是和服务在同一内网区域,带宽的影响可以忽略
- clickhouse 列式数据库,在处理关联查询上相比行式数据库需要读取的数据量更小,优势明显,未来有机会考虑在 event log 这类场景使用这个数据库
- mysql 传统的、关系型
- 进程内存存储和以上存储方式最显著的区别是:
进程内存是对象数据(反序列化后的数据),后者取出来的数据都是需要经过反序列才好再序列化成消息数据给到客户端;一些离线数据场景,也可以直接存储需要给到客户端消息的序列化后的数据在redis/db;具体需要看应用场景;考虑是否需要进程对象的(反序列后)lru
事务ACID
- Atomicity 原子
对数据的所有更改都像单个操作一样执行。也就是说,要么执行所有更改,要么不执行任何更改。例如,在将资金从一个帐户转移到另一个帐户的应用程序中,原子性属性可确保如果从一个帐户成功借记,则相应的贷记将记入另一个帐户。
- Consistency 一致
当事务开始和结束时,数据处于一致状态。例如,在将资金从一个帐户转移到另一个帐户的应用程序中,一致性属性可确保两个帐户中的资金总价值在每次交易开始和结束时相同。
- Isolation 隔离
一个事务的中间状态对于其他事务是不可见的。因此,并发运行的事务看起来是串行化的。例如,在将资金从一个帐户转移到另一个帐户的应用程序中,隔离属性可确保另一笔交易在一个帐户或另一个帐户中看到转移的资金,但不能在两个帐户中看到转移的资金,也不能在两个帐户中都看到转移的资金。
- Durability 可用
事务成功完成后,即使发生系统故障,数据更改也会持续存在并且不会撤消。例如,在将资金从一个帐户转移到另一个帐户的应用程序中,持久性属性可确保对每个帐户所做的更改不会被撤销。
测试

安全
工具
windows/桌面系统
- wireshark、fiddler 查看网络、数据包问题,对于手机端,需要一个移动wifi,只能在电脑上抓包
- procexp、tcpview 已经是必然被放在开始菜单自定义组的工具了,分别对应查看进程信息、链接情况
- postman http消息测试,现在也支持websocket了
- terminal: tabby 可以分屏是我比较关注的功能
linux/命令行
- htop
- tcpdump
- nc
- 临时监听端口:nc -l 51300. 客户端有链接断开后,监听端也会跟着关闭
- 监听端口:nc -lk 51300. 客户端有链接断开后,监听端不会关闭
- tc
运维
负载
- pre: 大区的游戏越来越多了,或者说混服的玩法越来越多了;过去分区一方面是技术上大区很麻烦,一方面是避免晚来的玩家输在起跑线太多;然后游戏一直在开区、滚服、合服。平台开发基本都是分布式的部署,负载均衡是个很重要的名词
- 物理机:机房多活(反亲和):部署选机器的时候需要避免机器在同一机房,免得机房整体故障
- 如果机房间网络链路优化的不好,多了几次路由、交换机这样的跳转点设备,会导致高并发量下,内部网络转发有一定的差距(没实测过)游戏的场景不太考虑这个问题,并发量远没有达到
- 域名:DNS 负载:在dns上给一个域名映射多个ip,用轮询、随机、负载、区域解析等条件负载到不同ip;之前游戏在全球部署,尝试使用公司内部dns区域解析的负载方式,但是测试结果不好经常判断错误;
- lvs/haproxy/nginx 网络负载、代理:这种是开发接触最多的部分了;经常用到的:
- ha tcp层的端口映射,8001端口映射转发到 10.1.2.100:8000 端口,8002到 10.1.2.101:8000 端口;
- nginx:可以做很多规则,到不同服务、不同进程,卸载tls….需要提前设计利用好 http header
- 进程、服务内部的负载:上面一些负载策略一般都比较简单,着重在转发需求上,服务内部的负载则比较多考虑服务当前的业务压力,比如当前多少玩家在这个进程上;多数由注册发现进程统计、记录服务负载信息(类似zookeeper、eureka…)比如匹配服务匹配完成需要找一个可用的负载相对较低的战斗服把玩家信息给过去
部署:网络、业务、数据分离
- 网络分离比较容易理解,不想服务所在的宿主机对外暴露,透明的网络层加规则也更方便内部负载扩容,比如nginx
- 如果是带tls的需求,对外的服务需要载入证书卸载tls(比如常用的nginx),而内部服务一般不需要tls(比如mysql需要一般都会关闭tls)
- 业务服务器是最容易出问题(资源耗尽、crash、无响应)
- 数据分离一个是因为数据部分的服务器不能对外(相对网络)、需要稳定(相对业务),另一个原因是数据服务器(mysql、mongodb)这种一般需要禁用
transparent_hugepage(THP)- THP 是linux为了提高内存分配效率的东西,一般
1 page = 2M,系统分配内存是先分配虚拟内存地址,需要使用的时候发现没有映射物理内存,内核触发page fault分配物理内存,普通页大小是4k;1G虚拟内存以4K分配的时候需要1G / 4K = 256 * 1024次;如果是 THP 的 2M 页只需要1G / 2M = 500次page fault以此得到更高的效率;但是对于数据库这种访问分散的数据,一次分配2M会造成大量的内存碎片,比如mongoDB 官网表示建议禁止 THP;mongo 官网解释的更直接,也给了禁用的方法; 这个是 mongoDB 宿主机设置的另一个建议1
2
3
4
5
6$ cat /proc/meminfo | grep -i 'hugepage'
HugePages_Total: 0 -- 分配了多少页
HugePages_Free: 0 -- 空闲多少页
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB -- 一页多大
- THP 是linux为了提高内存分配效率的东西,一般
问题分析
- 遇事不要慌,能保留现场先保留现场
- 不能保留现场的先记录时间点、备份当时的监控、core、log等可以帮助分析问题的信息
- 有需要的话能重启先重启,重启前需要判断是否需要回档等,需要回档的话先拉维护,把流量切走
- 问题已经出了,不要焦虑,确定问题解决问题才是重点

运营
迭代
管理
像简介里说的,我一直在写代码,管理上其实没太多经验;
没有尝试、实践、验证过的东西都是不确定、怀疑的态度,经常忽略方法论
之前领导明确指出过需要关注方法论的问题,可能我的学习过程总习惯有面镜子参考,之前的同事也都是实战的样子,这个点一直没有做好
当前的工作中看到一个很注重方法论的同事,也正在强迫自己学习这个点;用
强迫是因为可能他已经确定了自己是朝着管理方向走的,太多只关注方法论可在实际写代码上拉下太多了,这个样子又让我觉得不应该,就在我需要学习和以此为耻之间反复横跳只关注方法论问题很明显,
- 比如知道想要提高性能可以做缓存,可实现上release的时候把可复用的数值(比如object uuid)缓存了,get的时候却没有先从缓存拿,导致缓存暴涨;
- 再比如我这边做的一些重构核心代码、关键点上都有注释说明,重构过程中的思路、问题点最后会整理成文档放在wiki上,可是同事更倾向直接问为什么这么做,我的内心(代码文档都在你会自己看的么….),好像他只关心这个东西如果换他跟别人讲应该怎么讲,一个只是讲方法论的问题
- 并且听完思路表示和他设想的是差不多的,我的内心(那倒是实现掉呀….)
- 这位有很强方法论的同事不是我认为好的样子,剥离开只关注他好的地方也容易被日常零碎的事情影响着不想变成这样子
不过计算机是一个既定模式的学科,非0既1,不像生物、物理;而且工作只是在应用层,不像芯片制造那种开发需要基础设计、制造的理论;总的来说其实是个简单的东西,我不是个特别有天赋的人,只能勤补拙
这样子看其实我需要的可能是相信自己基于基础知识的推断,在架构设计上抓住需要解决问题的重点,不过分在没有实践验证、不够完善这些问题上慌张,更多的时间用来扩宽视野,用新的技术解决新的问题
之前晋升答辩,架构设计上注册发现是个单点,因为觉得是个很简单轻量的服务,没想着做成高可用的,可是答辩被老师问到楞在怀疑挂掉重启这个操作是不够的,一下子就不自信了(设计上做了挂掉也不影响其他服务正常运行的样子),这个场景记忆深刻;
还是那次答辩,在业务贡献和技术深度两个大方向上选了技术深度,主要的内容基本只在一个技术点上,领导一直觉得需要多加点内容,即使不是我负责的内容,怯懦也实诚的性格没有加更多的东西,答辩被问细节到用了多大mtu,庆幸也只有是自己实际做的才会关注着这个细节
这些好像和管理并没有太多关系,也还确实没有太多管理的内容记录
游戏开发的工作内容和制造业的定件很像,需求可以被明确到结果的样子,经历了这么多年也几乎没有不可被实现的需求(即便优化不下来的面片也有硬件的更新承载)
当前是996的状态,受《重来1、3》这本书和其他可能很多方面可能有成熟却越来越没有激情、身体相比没有10年前的活力的影响,抗拒又无能为力当前的状态,自上传导一个理念比自下向上传导要容易得多,当下所处的环境确实是这样的,我没有信心把我认为好的管理想法传导到上级,索性就被动的被推着走;想到已故的左耳朵耗子,致敬
游戏是一个大众产品,和绝大多数工业产品一样明确的分工可以让人专注、发挥所长,明确职责搭建完整产品;我相信每个人都有产品思维,严谨思考更多受态度影响,这可以弥补可能不好改动的设计上的不足;比如一个商店售卖功能,遇到问题发现需要检查客户端输入的购买数量是否合法
- A同学:找到对应位置,添加if语句
- B同学:联想到是否开宝箱等批量使用物品的功能也有类似问题,检查、修改相关代码
- C同学:对于客户端输入的地方都不能信任,数值是最容易越界的地方,考虑在协议层加一个通用的数值类型,根据不同的功能注册策略函数检查这种数值类型,覆盖数值、数值运算等可能越界情况
B同学已经是一个积极看待问题的样子了,如果团队里大部分都可以做到这个样子,这个产品在技术层面不会出现太多太严重的问题;保持积极多思考的样子,之后也会用更完善的设计来提前避免这类问题
我相信即便是刚入行的程序,明白具体原因都会发散考虑到其他类似场景;可是当前看到的大都是A同学,甚至下次写的时候还是会有相同的问题
开发人员停止思考,边缘化技术能力的价值,像是拿着不再打磨而锈迹斑驳的凿刀,像是用灰黄的泥土修补破损的玻璃雕像
- 重复、繁重工作让人觉得工作只是工作这件事情?那么看到新的技术、设计,完成、优化了一个小东西会兴奋一下么?
- 发觉技术的迭代并不能解决自己朝10晚10的状态,干脆得过且过?
- 不一致的想法却无能为力的样子放弃了对项目的想象和热爱?
- 看到抄捷径、卷加班还没有摔跤甚至得到更多糖果时,是想也这么做还是放弃挣扎了呢?
- 或者阴差阳错选错了行业?
- 还有什么让你觉得不适合、甚至厌恶了当前的工作甚至这个行业?
这是否是人们对经历的当下丧失或者抗拒了敏感,为什么会这样?如果我是一个管理者,会探究这个问题
我理解产品和代码是两回事,也许作为一个管理者在商业的思维下探究的是产品,可作为一个技术管理者需要完全丢弃技术价值才能实现产品理想的探究么?
摘自:https://mp.weixin.qq.com/s/HoFSNCd1U3eoUqYaQiEgwQ
谚语曰: “Talk Is Cheap, Show Me The Code”。知易行难,知行合一难。嘴里要讲出来总是轻松,把别人讲过的话记住,组织一下语言,再讲出来,很容易。设计理念你可能道听途说了一些,以为自己掌握了,但是你会做么?有能力去思考、改进自己当前的实践方式和实践中的代码细节么?不客气地说,很多人仅仅是知道并且认同了某个设计理念,进而产生了一种虚假的安心感——自己的技术并不差。但是他根本没有去实践这些设计理念,甚至根本实践不了这些设计理念,从结果来说,他懂不懂这些道理/理念,有什么差别?变成了自欺欺人。
重构 · 习惯的东西更得心应手,也是禁锢自己的枷锁
过往基本上都是自己在做事情,从0-1的做,review别人的代码也更多的是看一些完整、规范、细节等;这份工作才真正意义上重构一份代码;到目前为止2023.01-2023.08主要重构了场景、aoi、对象继承关系、对象管理、背包、定时器;记录一些可执行的实践
- 先要了解这是个什么类型的游戏,有那些过往经验是可以参考的;比如当前这款是2D MMO,于我参考的比较多的是之前做端游的经验
- 看下过往代码的问题,构想好重构后是什么样子的,解决了什么问题(代码很乱也是很严重的问题);比如之前的背包操作,添加一个物品有10几种函数实现,扣除等比量,很多实现看起来严格的写法(开宝箱)是先遍历检查物品够不够->检查背包剩余格子够不够->遍历扣除->遍历添加,大段大段类似的代码,重构目标很清楚: 用事务的方式操作背包,操作失败回滚就是,成功了最后commit,commit是void返回值的调用。
- 捡自己更好cover住的方式:对象模型上,ecs的模型近些年很流行,但是我更熟悉继承方式,而且对于MMO也还是觉得继承方式的对象在场景里处理更直接
- 我也热衷追求、使用新的技术,互联网是个瞬息万变的行业,业务推进技术的迭代、演进、革新,遇到新的问题,应该尝试研究、引入新的技术去解决问题,如果一味用老的技术或者架构无法支撑技术的演进,那么这个团队、架构应该是有问题的
- 具体操作上:
- 简化日志
friend std::ostream& operator << (std::ostream& os, xxx* so),日志是重构过程中很重要的一个点,做好简化,区分级别,先多记录日志 - 简化判定
1
2
3
4 - 明确好名词,并严格按照这个名词规则来
- 地图 -> map
- 场景 -> scene
- 配置id -> meta_id
- 唯一id -> uuid
- 用命名空间、用 using rename,一方面可以很直接找到重构用的代码,另外在重构过程中发现数据类型定的不合适还方便修改
1
2
3
4
5namespace map_v2 {
using map_meta_id = uint32_t;
using map_uuid = uint64_t;
static constexpr map_meta_id invalid_meta_id = 0;
}; // end namespace map_v2 - 合并原有相同作用的函数,一起替换
- 多用
explicit、final、const、enum class等带有限定作用的关键字,多让编译器就检查出问题(平时编码也该如此)
- 简化日志
- 命名上,不喜欢带数据类型的命名方式
m_dwID -> m_id(换数据类型更轻松,auto一样),相比驼峰更喜欢下划线m_metaId也可以是m_metaID那不如用m_meta_id - 很可能遇到重构过程中,改完之前无法测试的情况,耐心、耐心
- 用好 git,diff 工具,很方便
中间件
lb/lvs/nginx
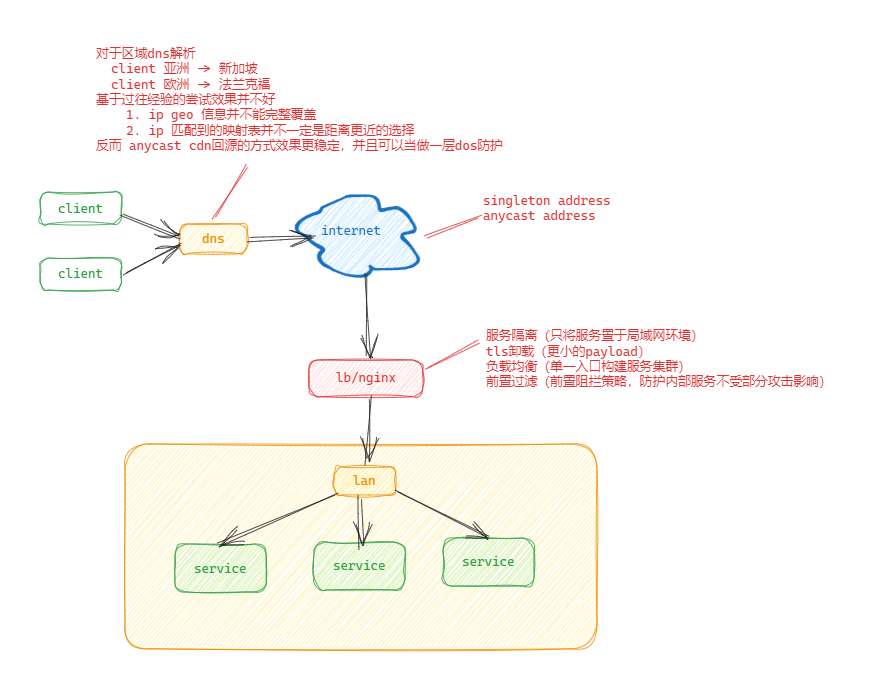
message queue
- 没有MQ
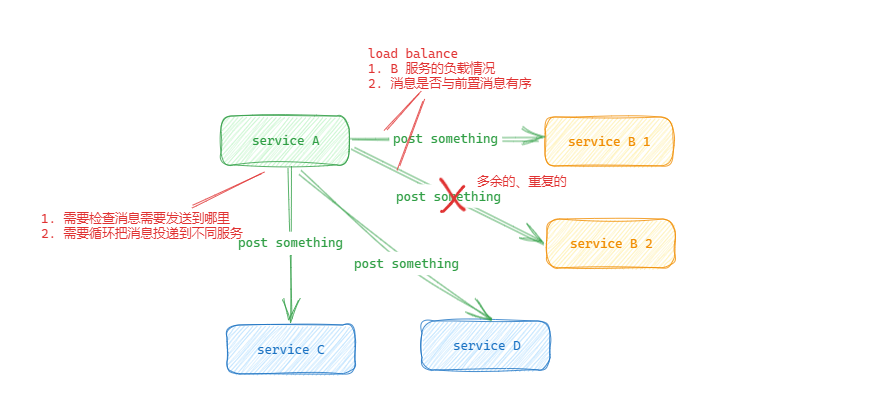
- 有MQ
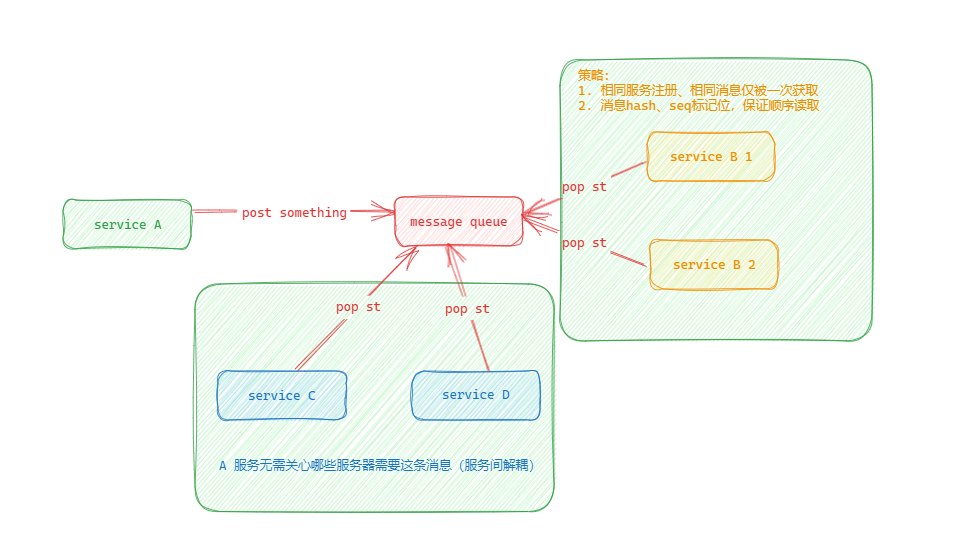
- 没有MQ
redis(常用的用途)
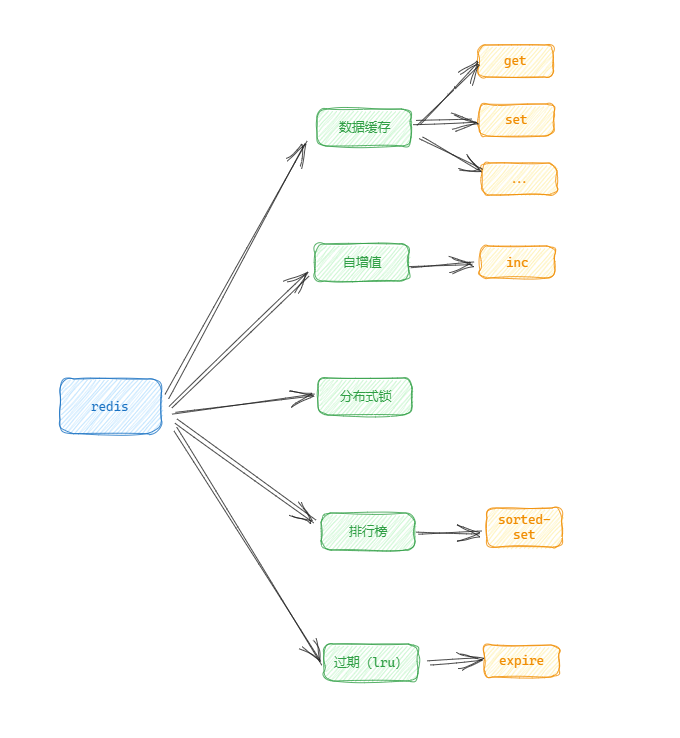
杂乱的零件
static variable
https://stackoverflow.com/questions/3837490/initializing-a-static-variable-in-header
- 头文件有一个
static global variable数据的生命,2个引用头文件的地方将产生2个数据副本; - 用c++的方式解决办法是放到类的成员函数里,作为成员函数的局部变量
- C++11 magic static
thread-safe之后,static使用越来越多
(https://blog.mbedded.ninja/programming/languages/c-plus-plus/magic-statics)
这个问题比较容易被踩到;理解原因的同时换种方式,习惯性加上namespace,习惯性把class作为namespace的空间域
1 | class test { |
std::this_thread::sleep_for
- windows 和 linux 不一样:https://github.com/gabime/spdlog/issues/609
std::min/max; #define min/max 冲突:
https://stackoverflow.com/questions/13416418/define-nominmax-using-stdmin-max
- visual studio pre-define 添加
NOMINMAX - 或者在 include win 头文件之前
1
2
3
4
template 问题
使用 luaBridge 的时候遇到一个问题,大意是这样:
1 | class super_cls { |
- 这里编译会报错:
no matching function for call to addFunction.... - 解决办法很简单,修改为
.addFunction("super_func", static_cast<void(sub_cls::*)()>(&sub_cls::super_function))即可 - 分析这个问题的原因(自己的理解):
addFunction是模版方式,属于编译期多态,sub_cls是继承方式运行期多态,调用addFunction的模版无法再编译期推导运行期的继承关系,也就无法匹配到super_function对sub_cls也是可见的 - 但是:这种写法在做模版的时候经常写,比如
std::bind(&sub_cls::super_function, sub_cls_point)是没有问题的 另一段代码:1
2
3
4
5
6
7
8template<class _Cls, class _Ret, class... _Args>
void caller(_Ret(_Cls::*func)(_Args...)) {
}
// test
caller(&sub_cls::super_function); // ok:func=(void (super_cls::*)(super * const))
caller<sub_cls>(&sub_cls::super_function); // error: no matching function for call to caller.... - luaBridge 也是类似报错行的方式,类的类型是从
deriveClass调用萃取出来的,导致addFunction写法报错 - visual studio 上述写法可以编译通过,应该是做了类似
is_base_of或者其他什么原因,没有细究
windows TCP SO_REUSEADDR and SO_EXCLUSIVEADDRUSE
- msdn: https://learn.microsoft.com/zh-cn/windows/win32/winsock/using-so-reuseaddr-and-so-exclusiveaddruse?redirectedfrom=MSDN
- stackoverflow: https://stackoverflow.com/questions/14388706/how-do-so-reuseaddr-and-so-reuseport-differ
- SO_REUSEADDR: 基本不应该被使用,没有使用组播(多播)方式的情况下,多个进程可监听统一IP+端口,但是只有1个进程可以收到消息
- SO_EXCLUSIVEADDRUSE: 表现同linux
- 端口占用与唤起其他进程问题:
1
2
3
4
5
6
7
8
91. A 进程 listen port: 52800
2. system('.\B.exe'); 唤起 B 进程
3. 关闭 A 进程,52800 端口可以在 TCPView 看到还在监听状态
4. 这时候再开启 A 进程将 bind 端口失败
5. 关掉 B 进程,52800 端口就会释放出来
解决方式:
使用 CreateProcess 替换 system 指令
暂时没有细究为什么