前言
关于系统性能优化,Netflix团队的一篇Blog写的很实用;https://netflixtechblog.com/linux-performance-analysis-in-60-000-milliseconds-accc10403c55
正文
你登录到一个有性能问题的linux服务器,第一分钟检查什么?
在Netflix,拥有庞大的EC2 linux云和众多性能分析工具来监控和侦察性能。包括用于云范围监控的Atlas和用于分析的Vector。虽然这些工具帮我我们解决了大多数问题,但我们又是需要登录到linux实例上,并运行一些标准的linux性能工具。
First 60 Seconds: 概要
在这篇文章中,Netflix性能工程管对将向你展示命令行优化性能探查的前60s,使用标准的linux工具,通过运行一下10个命令,你可以在60s内对系统资源使用情况和正在运行的进程有一个更高层次的了解。查找错误(error)和饱和度(saturation)指标,因为他们都很容易表示,以及资源利用率。饱和度是指一个资源的负载超过了他能处理的范围,可以通过请求队列的长度(length of a request queue)或者等待的时间(time spent waiting)来显示。
1 | uptime |
其中一些命令需要安装sysstat软件包。这些命令返回的内容将帮助你完成一些 Use Method : 一种定位性能瓶颈的方法。这包括检查所有资源 (CPU、内存、磁盘等) 的利用率、饱和度和错误指标。还要注意什么时候检查和排除某种资源,因为通过排除法,可以缩小研究目标,并指导后续的检查。
以下总结了这些命令,并提供了生产系统的示例。有关这些工具的更多信息,请参与他们的man pages。
1. uptime
1 | $ uptime |
这是一个快速的方法来查看系统平均负载情况,表示了要运行的任务(进程)的数量。在linux系统上,这些数字包含希望在CPU上运行的进程,以及在不间断I/O(通常是磁盘I/O)中阻塞的进程。他给出了资源负载(或者需求)的高级概念,但如果没有其他工具配合就无法正确理解。仅值得快速浏览一下。
这三个数字是具有 1 分钟、5 分钟和 15 分钟常数的指数阻尼移动总和平均值。这三个数字让我们对负载如何随时间变化有一些了解。例如,如果您被要求检查有问题的服务器,并且 1 分钟值远低于 15 分钟值,那么您可能登录太晚而错过了问题。
在上面的示例中,平均负载显示最近有所增加,1 分钟值达到 30,而 15 分钟值达到 19。这么大的数字意味着很多东西:可能是 CPU 需求; vmstat 或 mpstat 将确认,这是本序列中的第3和第4条命令。
2. dmesg | tail
1 | $ dmesg | tail |
这将查看最近 10 条系统消息(如果有)。查找可能导致性能问题的错误。上面的示例包括 oom-killer 和 TCP 丢弃请求。
不要错过这一步! dmesg 总是值得检查。
3. vmstat 1
1 | $ vmstat 1 |
vmstat(8)是虚拟内存统计 (virtual memory stat) 的简称,是一个常用的工具(几十年前首次为BSD创建)。它在每一行上打印关键服务器统计数据的摘要。
vmstat运行时的参数为1,以打印一秒钟的摘要。第1行输出(在这个版本的vmstat中)有一些列显示自启动以来的平均数,而不是前一秒。现在,跳过第1行,除非你想学习并记住哪一列是哪一列。
要检查的列:
r :在CPU上运行并等待轮次的进程数量。这提供了一个比负载平均数更好的信号来确定CPU的饱和度,因为它不包括I/O。解释一下:一个r值大于CPU的计数就意味着饱和。free :以千字节为单位的可用内存。如果要计算的位数太多,则您有足够的可用内存。包含在命令 7 中的free -m命令更好地解释了空闲内存的状态。si, so :换入和换出。如果这些不为零,则表示内存不足。us, sy, id, wa, st :这些是CPU时间的细分,是所有CPU的平均时间。它们是用户时间、系统时间(内核)、空闲时间、等待I/O时间和被盗时间(被其他客体,或在Xen中,客体自己的隔离驱动域)。
CPU 时间细分将通过增加 用户 + 系统 时间来确认 CPU 是否繁忙。恒定程度的等待 I/O 指向磁盘瓶颈;这是 CPU 空闲的地方,因为任务被阻塞,等待挂起的磁盘 I/O。您可以将等待 I/O 视为 CPU 空闲的另一种形式,它可以提供有关它们为何空闲的线索。
系统时间对于 I/O 理是必要的。超过 20% 的高系统时间平均值,进一步探索可能会很有趣:也许内核处理I/O的效率很低。
在上面的例子中,CPU时间几乎完全在用户层面,而是指向应用程序层面的使用。CPU的平均利用率也远远超过90%。这不一定是个问题;使用 r 列检查饱和程度。
4. mpstat -P ALL 1
1 | $ mpstat -P ALL 1 |
此命令打印每个 CPU 的 CPU 时间故障,可用于检查不平衡。单个热 CPU 可以作为单线程应用程序的证据。
5. pidstat 1
1 | $ pidstat 1 |
pidstat 有点像 top 的 per-process 摘要,但打印滚动摘要而不是清除屏幕。这对于随着时间的推移观察模式很有用,还将您看到的内容(复制-粘贴)记录到您的调查记录中。
上面的示例将两个 java 进程标识为负责消耗 CPU。 %CPU 列是所有 CPU 的总数; 1591% 表明 java 进程消耗了将近 16 个 CPU。
6. iostat -xz 1
1 | $ iostat -xz 1 |
这是了解块设备(磁盘)、应用的工作负载和由此产生的性能的绝佳工具。
重点关注:
r/s, w/s, rkB/s, wkB/s:这些是交付给设备的每秒读数、写数、读KB和写KB。使用这些来描述工作负载。一个性能问题可能只是由于应用了过多的负载。await:I/O 的平均时间(以毫秒为单位)。这是应用程序遭受的时间,因为它包括排队时间和服务时间。大于预期的平均时间可能是设备饱和或设备问题的指标。avgqu-sz:向设备发出的平均请求数。大于 1 的值可能是饱和的证据(尽管设备通常可以并行处理请求,尤其是前置多个后端磁盘的虚拟设备。)%util:设备利用率。这实际上是一个繁忙的百分比,显示设备每秒钟进行工作的时间。大于60%的数值通常会导致性能不佳(应该在等待中看到),尽管这取决于设备的情况。接近100%的值通常表示饱和。
如果存储设备是一个逻辑磁盘设备,面向许多后端磁盘,那么100%的利用率可能只是意味着一些I/O在100%的时间被处理,然而,后端磁盘可能远远没有饱和,可能能够处理更多的工作。
请记住,性能不佳的磁盘 I/O 不一定是应用程序问题。许多技术通常用于异步执行 I/O,因此应用程序不会直接阻塞和遭受延迟(例如,读取的预读和写入的缓冲)。
7. free -m
1 | $ free -m |
右边两列显示:
buffers:对于缓冲区缓存,用于块设备 I/O。cached:用于页面缓存,由文件系统使用。
我们只是想检查它们的大小是否接近于零,这会导致更高的磁盘 I/O(使用 iostat 确认)和更差的性能。上面的例子看起来不错,每个都有很多 MB。
-/+ 缓冲区/缓存 为已用和可用内存提供了较少混淆的值。 Linux 将空闲内存用于缓存,但如果应用程序需要,可以快速回收它。所以在某种程度上,缓存的内存应该包含在空闲内存列中,这一行就是这样做的。甚至有一个网站 linuxatemyram 是关于这种混淆的。
如果使用linux上的ZFS,就像我们在一些服务中所做的那样,这可能是额外的混乱,因为ZFS有它自己的文件系统缓存,并没有被free -m列正确反映出来。看起来系统的可用内存很低,而实际上这些内存在需要时可以从ZFS缓存中使用。
linux ate my ram:
- 这是怎么回事?
Linux 借用未使用的内存用于磁盘缓存。这使您看起来好像内存不足,但实际上并非如此!一切都好!- 为什么要这样做?
磁盘缓存使系统更快,响应更快!除了让新手感到困惑之外,没有任何缺点。它不会以任何方式占用应用程序的内存,永远不会!- 如果我想运行更多应用程序怎么办?
如果你的应用程序想要更多的内存,他们只需拿回磁盘缓存借来的一大块。磁盘高速缓存总是可以立即还给应用程序的 你的内存并不低!- 我需要更多的交换区吗?
不,磁盘缓存只是借用了应用程序目前不需要的内存。它不会使用交换空间。如果应用程序想要更多的内存,他们只是从磁盘缓存中拿回来。他们不会开始交换。- 我如何阻止 linux 这样做?
你不能禁用磁盘缓存。任何人想禁用磁盘缓存的唯一原因是,他们认为磁盘缓存占用了他们的应用程序的内存,其实不然。磁盘缓存使应用程序的加载速度更快,运行更流畅,但它永远都不会占用内存。因此,绝对没有理由禁用它。
然而,如果你发现自己需要快速清除一些内存来解决另一个问题,比如一个虚拟机表现不佳,你可以用echo 3 | sudo tee /proc/sys/vm/drop_caches强制linux无损地丢弃缓存。- 如果不是,为什么 top 和 free 会说我的所有 ram 都已使用?
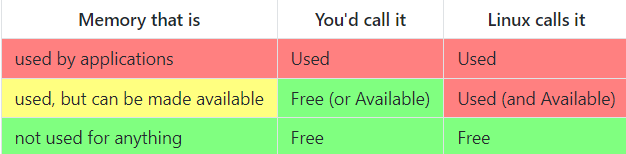
这只是术语上的差异。您和 linux 都同意应用程序占用的内存是used的,而没有用于任何事情的内存是free。
但是,您如何计算当前用于某事但仍可供应用程序使用的内存?
您可能会将该内存视为free和/或available。 Linux 将其视为used,但也将其视为available:
这个something(大致)就是top和free所说的buffers和cached。由于您的和 linux 的术语不同,您可能会认为自己的内存不足,但实际上并非如此。- 我如何查看我真正拥有多少可用内存?
要查看您的应用程序在不交换的情况下可以使用多少内存,请运行free -m并查看available列:(对于 2016 年之前的安装,请查看
2
3
4
total used free shared buff/cache available
Mem: 1504 1491 13 0 855 792
Swap: 2047 6 2041-/+ buffers/cache行中的free列。)
这是你的答案,单位是MIB。如果你只是天真地看着used和free,你会认为你的内存是99%,而实际上只有47%!
关于Linux计算的avaukavke的更详细的技术描述,请看添加该字段的提交。- 我应该什么时候开始担心?
一个 健康的、有足够内存的Linux系统 在运行一段时间后,会出现以下预期的、无害的行为:
free内存接近 0used内存解决内存总量available内存 (或者free+buffers/cache) 有足够的空间 (比如:总数的 20%+)swap used没有变化
警告信号 真正的低内存的情况:available内存 (或者free+buffers/cache) 接近于 0swap used增加或者波动dmesg | grep oom-killer显示有 outofmemory-killer 的内容- 我如何验证这些事情?
有关更多详细信息以及如何试验磁盘缓存以显示此处描述的效果,请参阅此页面。很少有事情比在您自己的硬件上测量一个数量级的加速更能让您欣赏磁盘缓存!
8. sar -n DEV 1
https://linux.die.net/man/1/sar
1 | $ sar -n DEV 1 |
使用此工具检查网络接口吞吐量:rxkB/s 和 txkB/s,作为工作量的衡量标准,并检查是否已达到任何限制。在上面的示例中,eth0 接收达到 22 Mbytes/s,即 176 Mbits/sec(远低于 1 Gbit/sec 的限制)。
这个版本也有%ifutil用于设备利用率(全双工的两个方向的最大值),这也是我们使用Brendan的 nicstat 来测量的东西。和nicstat一样,这很难搞清楚,而且在这个例子(0.00)中似乎不工作。
9. sar -n TCP,ETCP 1
https://linux.die.net/man/1/sar
1 | $ sar -n TCP,ETCP 1 |
这是一些关键 TCP 指标的汇总视图。这些包括:
active/s:每秒本地发起的 TCP 连接数(例如,通过 connect())。passive/s:每秒远程启动的 TCP 连接数(例如,通过 accept())。retrans/s:每秒 TCP 重传次数。
主动和被动计数通常作为服务器负载的一个粗略衡量标准:新接受的连接数(被动),以及下游连接数(主动)。把主动看作是出站,把被动看作是入站,可能会有帮助,但这并不严格正确(例如,考虑一个本地主机到本地主机的连接)。
重传是网络或服务器问题的标志;它可能是一个不可靠的网络(例如,公共互联网),或者可能是由于服务器过载并丢弃数据包。上面的例子只显示了每秒一个新的 TCP 连接。
10. top
1 | $ top |
top 命令包括我们之前检查过的许多指标。运行它可以很方便地查看是否有任何内容与之前的命令有很大不同,这表明负载是可变的。
top 的一个缺点是随着时间的推移很难看到模式,这在提供滚动输出的 vmstat 和 pidstat 等工具中可能更加清晰。如果您没有足够快地暂停输出(Ctrl-S 暂停,Ctrl-Q 继续),也可能会丢失间歇性问题的证据,并且屏幕会清除。
后续分析
您可以应用更多命令和方法来进行更深入的钻探。请参阅 Velocity 2015 中 Brendan 的 linux 性能工具教程,该教程通过 40 多个命令进行工作,涵盖可观察性、基准测试、调整、静态性能调整、分析和跟踪。