前言
工作过程中对于一些问题的处理方案记录,也包含一些常用轻巧的伪代码
JAVA,C++
近几年工作,主语言从C++切换到了Java,当时最主要的原因是Java更适合快速开发(有较完备的轮子),Java是门有GC的语言,内存有较严格的管理,不会像C++一样容易出现内存问题;近些年流行的GO也是如此Q: 两者区别R: 最大的区别是在GC上。C++对于内存的使用,或者说所有权不明确,没有严格的限制(管理),这点上C++是一个开放的态度;带GC的语言对内存的管理更为严格,开发者更关注业务和框架本身。
CDN 强制回源
访问: cdn_domain/file?x=123 (一个随机数)确认: postman 这样的工具可以看下回执的header里面是否有类似 X-Cache 的值包含类似 Miss 信息
tc 命令
tc qdisc add dev eth0 root netem delay 100ms
这个是对网卡eth0 添加策略, 发送的数据包 延时100mstc qdisc add dev ens160 root netem delay 120ms 10ms
该命令将 eth0 网卡的传输设置为延迟 120ms ± 10ms (90 ~ 130 ms 之间的任意值)发送。tc qdisc add dev eth0 root netem loss 20% 40%
该命令将 eth0 网卡的传输设置为随机丢掉 20% 的数据包,成功率为 40% tc qdisc del dev ens160 root netem
重启网卡或者命令删除
日志解析
先截取第92-最后的字符,再以 } 分割截取倒数第二个 } 之前的所有内容,再补一个 },再替换 \" 为 "
1 grep 'BI' logs/aaa.log | cut -b 92- | rev | cut -d '}' -f 3- | rev | sed 's/$/}/g' | sed 's/\\"/"/g'
grep 结果逐行解析,取出eventTime时间戳转时间字符串,再组织输出
1 grep 'BI' aaa.log | cut -b 92- | rev | cut -d '}' -f 3- | rev | sed 's/$/}/g' | sed 's/\\"/"/g' | while read line ; do etime=$(echo $line | jq '.eventTime' | cut -b -10) ; xtime=$(date -d @$etime '+%F %T' ); echo "$xtime -> $line " ; done
1 2 3 4 5 6 grep "disconnect," aaa.log | grep '2020-10-13 18:00' | awk -F ' ' '{print $4}' > u.txt cat u.txt |while read id ; do echo $id ;grep $id aaa*.log |grep 'login success' ; echo ; done |tee /tmp/k.logcat /tmp/k.log grep city|awk -F: '{print $24}' |awk '{print $2}' |grep ^[0-9]|sort |uniq |while read ip; do res=` curl "https://www.sudops.com/ipq/?format=json&token=9a3061dc225dedc7d87e9ca02997b8de&ip=$ip " 2>/dev/null|grep -P -o 'desc1":.*' `; echo "$ip $res " ; sleep 1; echo ; done |tee /tmp/queryip_isp.txt
缺省情况下,各协议的老化时间为:
协议
时间
DNS
120 s
ftp
120 s
ftp-data
120 s
HTTP
120 s
icmp
20 s
tcp
600 s
tcp-proxy
10 s
udp
120 s
sip
1 800 s
sip-media
120 s
rtsp
60 s
rtsp-media
120 s
可用undo firewall-natsession { all | dns | ftp | ftp-data | http | icmp | tcp | tcp-proxy | udp | sip | sip-media | rtsp |rtsp-media } aging-time 命令恢复对应会话表项的超时时间为缺省值。
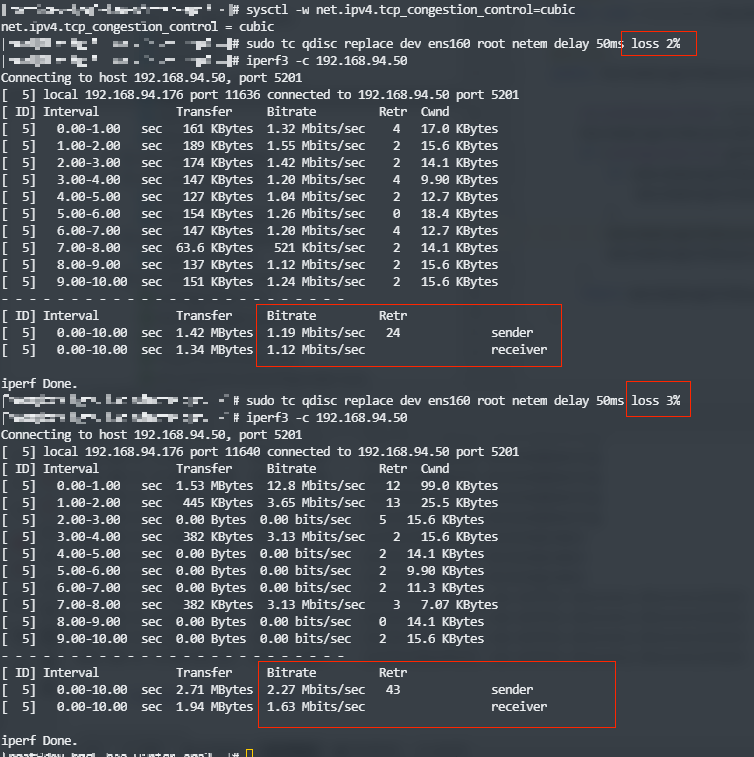
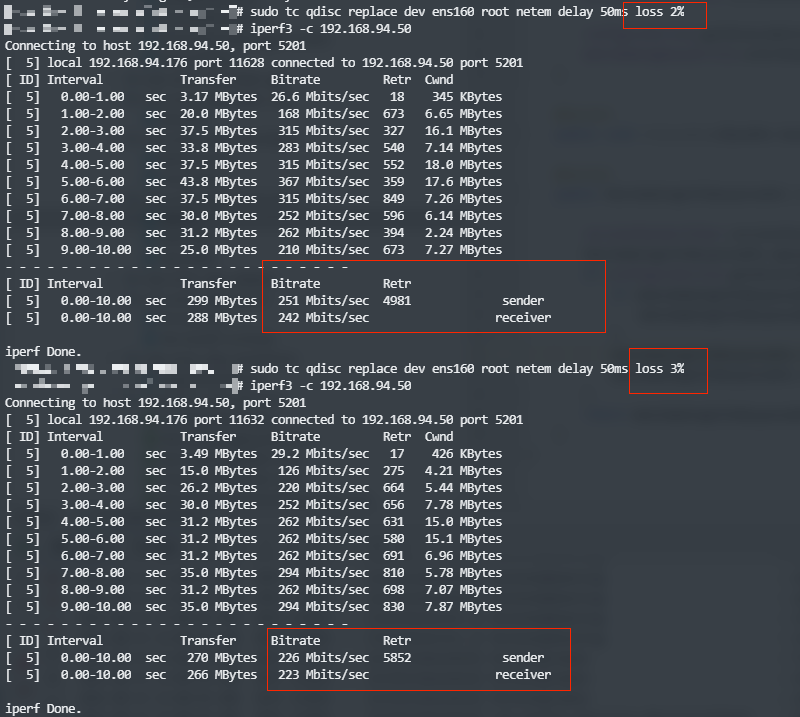
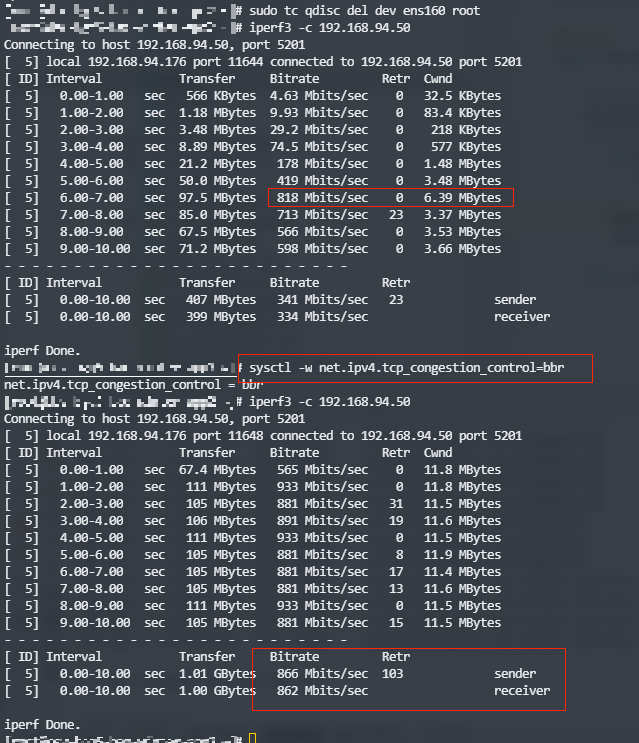
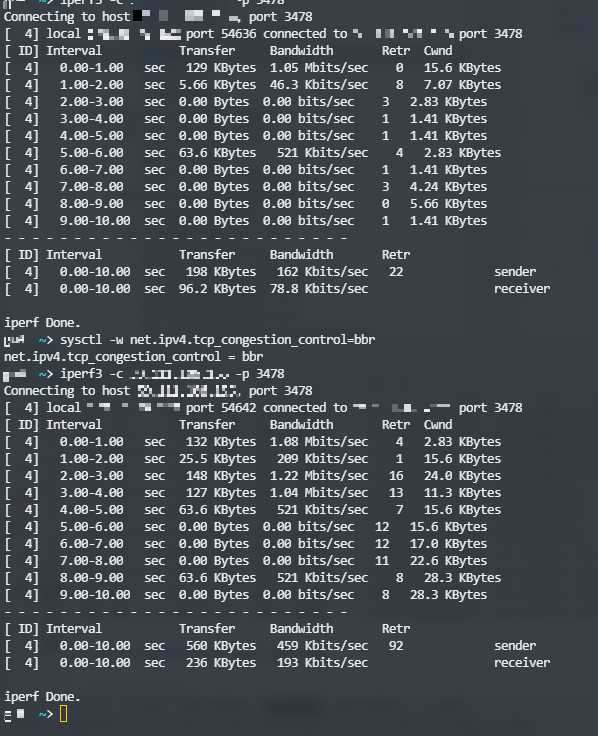
BBR/CUBIC 算法测试
cubic TC 内网测试
bbr TC 内网测试
去掉TC
tc只设置delay的时候两者差不多,但是一旦有了lose,差别就很大了公网:香港->杭州(杭州机器带宽小)
唯一ID
老生常谈的问题,但是这个问题在期望动态扩容架构上,使用传统的**雪花算法**不是特别方便,因为随时可能会加机器,但是加机器的时候就需要考虑给这个机器单独编码才行,面对这个问题反倒是老套的**依赖数据库跳级**的方式更简单了
Q: 雪花,redis自增 优缺点
R:
雪花优点: 不依赖数据库,可以根据自增位确定单位时间(一般是ms)最多的ID数量,也比较好确定算法可用的时长,一版是在80年+,对于大部分互联网业务,这都够用了雪花缺点: 强依赖时间,有回调问题需要处理;对于相同的服务,需要预先分配服务的占位Index,这个Index是有长度限制的;这方面对运维侧不友好(因为一般会把这个值放在启动项,会导致服务启动参数不同;当然也可以从数据库自己获取,先取到先占用,但是这样就又依赖了数据库)自增优点: 简单,除此之外好像其他都不明显自增缺点: 强依赖数据库(+redis),产出的ID需要混淆
Q: 雪花的回调处理
R: 一般的处理办法是缓存上次生成ID的时间,如果下次的时间比上次小,就不变更这个时间,并且用 ms 的 sequence 自增位的回调位标记,假设 sequence 有 4096(12bits) 可用,那么用最高位 1位标记回调,剩余每 毫秒 2048 个ID可用;如果遇到 反复回调,还是 报错交上层处理把
Q: ID混淆(避免外面很容易的猜到ID生成的规则)
R: 常用的方式是按位转换,比如每2位和另外2位的位置做交换,最后得到的依然是一个数值类型的值;实际业务中还有这个ID过长的问题,这里采用的是把最后的ID做下转码,比如常见的转成16进制,36进制;有转码的需求在,混淆也可以混在转码过程中,比如10进制的混淆把 0-9 数字随机打乱,然后做10进制->10进制的转码就好,到其他进制同理
1 2 echo "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" | fold -w1 | shuf | tr -d '\n'
Q: 多个区保证唯一R: 首先要给多个区编码,如果这个是登陆账号,那么需要架设一组global服务器,这个ID由global检查account没有在其他区注册过之后再生成
签名 token
最简单的token就是缓存在redis中的uuid了,只要有明确的重置、续期规则就好对于分布式系统,不想多个系统都依赖redis的情况下,token还会做成加密后的值Q: 具体方式R: 核心思想是一段可解析,一段作为验证,有时间戳概念。
定义一个加密Key列表,根据随机码(mn)从列表中选出一个加密Key;-> secure
基于当前时间戳一定偏移的ts;-> ts
ts、playerId 混淆后的 obscured -> obscured
组合:
验证部分:mn + obscured + secure 组合 md5 取部分字符
解析部分:mn + ts 组合的 hex 值
校验:
先解出2部分
从解析部分解析出 mn + ts
根据 mn 拿到 secure
根据 ts 和 playerId 解出 obscured
组合起来验证
额外:
这里也可以设置一个超时时间,如果这个 token 没有在本地redis中缓存,就校验 ts 是否超时了
因为这里认为正常逻辑里,玩家登陆后会请求覆盖到所有服务的数据
1 2 3 4 5 6 private static class Signature { public int mn; public long ts; public long obscured; };
防破解 - Timing Attack
简单的解释就是hack利用密码、token等一般验证(逐个字符验证,验证到错误字符停止并返回错误)中根据验证返回的时间判断到哪个字符出错了,暴力破解的一种
简单的应对如下代码1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 inline bool compare_const (const void * a, const void * b, const size_t size) if (a == nullptr || b == nullptr || size == 0 ) return false ; if (a == b) return true ; const unsigned char * _a = (const unsigned char *)a; const unsigned char * _b = (const unsigned char *)b; unsigned char result = 0 ; for (size_t i = 0 ; i < size; i++) { result |= _a[i] ^ _b[i]; } return result == 0 ; }
跨服务交互
服务器在同一局域网: 基于数据访问隔离的思想一般是S1向S2要数据,通常是RPC调用服务器不在同一局域网: 可以把数据做加密后由客户端带给服务器,这里加密(签名)方式有很多,不再赘述
确保玩家同一时间只在一个服务器区
这里假设有3个区:A, B, CA, B 都只能到 C: 有点像传统MMO的跨服玩法,一般的做法是 A 保存数据,标记玩家到 C 了,把数据带给 C,数据的保存还是要到 A 保存A, B, C 可以互相跳: 玩家从A到C,A检查玩家当前是在自己服务器的前提下,A先去C请求一个token,然后标记玩家此刻在C上,客户端后面用这个token去C交互
匹配服务
避免业务层的锁: redis standalone 下 lua,避免锁,lua 里面解析结构,在结构里做标记
避免死锁
避免嵌套锁std::mutex)),每个线程拿到一个锁之后,别再去获取另一个锁,每个线程只持有一个锁,如果一定需要锁多个,使用下面这些对获取锁的操作上锁
避免在持有锁时调用外部代码
控制好锁的粒度,使用固定顺序获取锁std::lock/std::scoped_lock 虽然可以锁多个互斥量,但是要求这些互斥量是一起作为入参的,如果出现不能使用这种方式的情况,就只好控制好锁的粒度,使用固定顺序去锁
对于一个可能会多次锁的对象,使用 std::recursive_mutex
服务器基础性能测试
1 sysbench --threads=N cpu --time=300 run
1 sysbench --threads=N memory --time=300 run
1 iperf3 -c {ip} -p {} -t 100
1 fio -filename=/data/test -direct=1 -iodepth=1 -thread -rw=randrw -rwmixread=50 -ioengine=libaio -bs=4k -size=20G -numjobs=1 -runtime=60 -group_reporting -name=mytest
一个程序的性能构成要件大概有三个,即算法复杂度、IO开销和并发能力。
语言艺术 - 通用函数简单封装
anyone & container single1 2 3 4 5 6 7 8 9 10 static auto anyone = [](auto && src, auto &&... args) -> bool { return ((args == src) || ...); };template <typename Container>static bool single (Container container) auto it = std::cbegin (container); return it != std::cend (container) && ++it == std::cend (container); }
自旋锁 spin lock1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class spin_lock { private : std::atomic_flag _flag = ATOMIC_FLAG_INIT; static const unsigned yield_stage = 16 ; static const unsigned nonsleep_stage = yield_stage * 2 ; public : bool try_lock () { return _flag.test_and_set (std::memory_order_acquire); } bool lock (unsigned max_count = std::numeric_limits<unsigned >::max()) { unsigned i = 0 ; for (; i < max_count && !try_lock (); ++i) { if (i < yield_stage) std::this_thread::yield (); else if (i < nonsleep_stage) std::this_thread::sleep_for (std::chrono::microseconds (0 )); else std::this_thread::sleep_for (std::chrono::microseconds (1000 )); } return i < max_count; } void unlock () { _flag.clear (std::memory_order_release); } };
instanceof (还需要修改,最好能做成java那种调用的样子)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 template <class _Src >class __instanceof {public : using base_type = _Src; public : template <class _Ty> bool instanceof () { return std::is_base_of<_Ty, base_type>::value; } }; template <class _Base , class _Xx , typename std::enable_if<std::is_class_v<_Base> && std::is_class_v<_Xx>, bool >::type = true > static bool instanceof () { return std::is_base_of<_Base, _Xx>::value; } template <class _Base , class _Xx , typename std::enable_if<std::is_class_v<_Base>&& std::is_class_v<_Xx>, bool >::type = true > static bool instanceof (_Xx xx) { return std::is_base_of<_Base, std::decay_t <decltype (xx)>>::value; }
弱网环境
服务端网络选型上尽可能离玩家更近、网络质量更好的地方和网络提供商
物理距离不能避免,但是也不是物理距离最近的就一定是最快的,线路的带宽(一定要预估好服务器需要的带宽,并且对带宽做监控,比如一旦超过50%就要准备扩了)、链路的拥塞程度、吞吐量、跨网络运营商(选多线IDC)很多因素影响
比如单独把对网络延迟要求高的服务分大区域部署多个服务节点(离玩家更近),这里需要服务端在逻辑上做好对玩家网络的判断和分配,最简单的方法在节点服务同机房开一个探测RTT的服务,客户端拿到区域内所有节点的IP,并行探测自行选择更优的节点;根据业务逻辑的需求,这个分配更可能是由玩家自主选择(类似MMO的分线、分区)、服务端基于一定指标(玩家IP所在区域、服务器存活、负载情况等)直接给玩家分配服务器;一些业务需要提前分配服务并下发Token类似的验签用于后续目标服务器对玩家身份和可进入的验签
可以选择 cloudflare/cloudfront 这种 anycast 的加速服务(CDN回源),大致原理是玩家先接入边缘节点,再回源到游戏服务器,网络供应商一般会对边缘节点到服务器的网络路由做优化(最优链路,减少跳跃点),而且一般会在边缘节点卸载TLS,减少RTT
修改系统里的一些网络参数:拥塞窗口大小、读写缓冲、time wait reuse/recycle、retransmission timeout等等
使用BBR的拥塞算法,可以减少拥塞重传窗口折半这种情况带来的影响,网络也更平滑
如果不是一定要DNS的,用IP就好,DNS也需要消耗1RTT,DNS本身就会有劫持、老化等很多问题
根据业务需要看是不是可以开多个链接并行发送消息,甚至是2种协议,比如用udp处理帧数据,tcp/rudp处理关键帧数据
2个比较出名的rudp:KCP,QUIC
KCP: 超发的处理方式,实际测试中效果并不好,弱网环境下的游戏表现也不好(之前没有做更深度的测试,最早我们游戏客户端的同步数据量很大,断网需要重新拉战场完整数据,对于这种很大的包KCP表现得延迟不如TCP好,可能和客户端当时的处理方式也有一定的关系,测试带宽也只有1M)QUIC: 已知目前IOS端在HTTP/S上已经优先选择QUIC/TLS1.3的方式了,quic替换长链接TCP的还没有实际应用过,需要TODO
如果也用的是TCP的长链接方式,对于手机端一定要自己定义异步的keepalive消息,避免切后台导致链接断开(unity update在切后台会停止);需要重连的时候,避免一个循环没有时间等待的反复重连重试,避免重连带给服务端瞬间的accept(半链接队列)压力
对于客户端的网络实现,优先分别给Android/IOS单独写,用系统上最优的socket,比如unity的webHttpSocket的封装,服务端支持的情况下,IOS端会优先用QUIC+TLS1.3的方式
短连接需要避免每次都要握手的情况(http keepalive、QUIC),长链接需要异步keepalive
打开TCP_NODELAY选项,这个基本是游戏里的默认选项了
尽量控制传输数据包大小在一个MSS内,避免分片,任何一个分片的出现丢失都可能会造成多次传输、确认(还有分片、拼接的开销);建议不要超过1400/1360字节,虽然MTU=1500情况下,TCP的MSS=1500 - 20(IP) - 20(TCP) = 1460,但是很多服务器、网络设备的MTU设置是小于1500的
协议编码上尽量用占字节少的二进制编码方式(protobuffer),减小包体大小,有必要的话做压缩,用CPU时间换网络时间
同步类型的消息尽量计算差异后再组包发送,而不是把所有都序列化到包里,数据对表现的驱动方式最好是状态类型的驱动,比如一个跑步的驱动,如果用状态可能只需要1-5个字节(标记枚举),但是要从动画驱动的话,一次跑动胳膊腿甚至手持的装备都是动画差异,包体也就更大了(游戏里我看到是先迈的左脚和你看到先迈右脚其实没有区别吧),这里也是要跟业务走,可以混合状态、动画驱动
减少双端同步量&处理量,避免无谓的消息处理和带宽占用。场景同步的游戏中,可以考虑在玩家处于某些状态的时候不要同步那么多事件到客户端;例如在九宫格地图(玩家一屏的可见视野是9个格子)中我正在打怪,而我攻击的最大范围只有一个格子,这时候服务端同步的主要内容应该集中在这一个格子里对象的事件,对于周边的其他格子信息,可以换成更小的数据包(减少客户端解析数据&处理数据的时间消耗),或者由客户端以lazy帧的频率主动向服务端请求变化信息(当然这样相比服务端主动推送多了1次RTT)关于让客户端主动请求的题外话:服务器端一般情况下对于每个客户端相同行为处理的消耗时间是相同的,也就是服务端会以相同的频率向客户端广播消息(排除一些时间服务端由于性能问题处理的差异),而客户端是玩家的设备,也就是不同设备支持的最高帧率、不同网络环境的延迟都是不一样的;客户端的处理事件需要一个个处理,可能A设备1档机处理一个事件1s(比较用的单位时间),B设备3档机需要3s,服务端以相同的频率给到2个客户端的消息,他们实际处理的效率是不一样的,无端的浪费了带宽;所以是不是或者至少在某些状态下,由客户端主动发起请求,服务端再回执而不是主动push到客户端表现会更好。在gateway做广播目标对象的筛选:这里认为传统服务器单个场景是在一个gameservice的,但是单个场景的玩家是在多个gateway的,一次事件gs只需要把事件本身(也就是消息同步的message-body)广播到gateway上,由gateway做需要广播玩家的筛选,因为gateway是多组并且可以水平扩展,这样子做可以减轻gs遍历玩家的成本,也减轻gs到gateway的带宽压力(即使常规认为内网通讯是1Gbps的带宽,跑了网络传输,大包和小包影响还是很大的);这样子做就需要gateway上有一部分场景的信息,比如九宫格放到gateway上,用二维(三维)数组方式空间换时间,拿到需要广播的对象,把消息广播出去客户端超发:前面提到了多个链接(甚至多种协议并行),但是这里需要做不同链接协议处理的解耦、合并等策略,需要看游戏是怎么拆分协议的,也需要看是不是有些协议上的丢弃在其他协议补偿之后可以足够满足游戏表现和数据上需要的内容;在这个基础上,如果用的是udp或者http的协议,如果用多通道超发的方式,也许能提高一些网络性能,但是会牺牲掉流量成本也会提高服务端的带宽压力;(由于拥塞控制的关系,tcp在这里是不合适的。)…….
还有很多没想到或者实际遇到处理的问题
防作弊 从安全性上来说,客户端计算 模型 远远弱于 服务端校验,而 服务端校验 又弱于 服务端计算
按键精灵类;
加速(变速齿轮类);
改内存数值(比如改合作回合数、改SP、锁血等);
破解游戏包(比如直接改骰子配置参数);
修改网络包,包括:拦截包、修改包、重放包等等;
脱机外挂类;
其他;
通常,作为典型加速器的速度档会改变过程时间。这意味着游戏客户端的内部时间比服务器快。我们可以检测服务器和客户端之间的时间,以判断玩家是否通过加速器作弊。这就是重点。
1 2 3 4 5 t0 t3 Server |---------------------------------------------| >>>> >>>> Client |-----------------------------------| t1 t2
t0:服务器向客户端发送初始化包(如游戏开始事件)。当前服务器时间为t0;
t1:客户端在从服务器接收到init数据包后的每个间隔(例如1秒)后发送一个心跳数据包。t1是指发送第一心跳包的客户端时间,也是客户端游戏的开始时间;
t2: 表示从客户端发送的最后一个心跳包的客户端时间;
t3: 是服务器完成游戏或服务器随时检测到作弊的服务器时间;
显然,我们可以安全地说(t3-t0)>=(t2-t1)。实际上(t3-t0)≈ ((t2-t1)+ TTL*1)。((heartheat_count+1)* interval)作为(t2-t1)。(t3-t0)*(1+冗余)>= ((heartheat_count+1)* 间隔)。例如,间隔可以是1秒,冗余可以是0.02。
即使正常玩家在游戏期间更改了操作系统时间,也很少会对他们造成伤害,因为我们使用心跳计数而不是客户端时间。我确实发现有些电脑的时钟芯片比平时快得多。但冗余保护了这种情况。因此,解决方案非常安全。
在服务端是2块的校验,包数量和时间;比如检测加速(10s或者300个移动包)检测一次距离
防破解
协议非对称加密交换秘钥,对称加密传输内容,保护好服务端私钥,防止中间人攻击。流式加密,同样包发2次内容不一样