std::shared_ptr
cppreference.com: (https://en.cppreference.com/w/cpp/memory/shared_ptr)
原本知道 shared_ptr refcount 是原子的,也就是线程安全的,但是并没有细究过内部在多线程下操作会有怎样的问题,是否是安全的
直到遇到一次因为 shared_ptr 的崩溃
网上关于std::shared_ptr线程安全的文章已经很多了,这里主要是记录和模拟崩溃
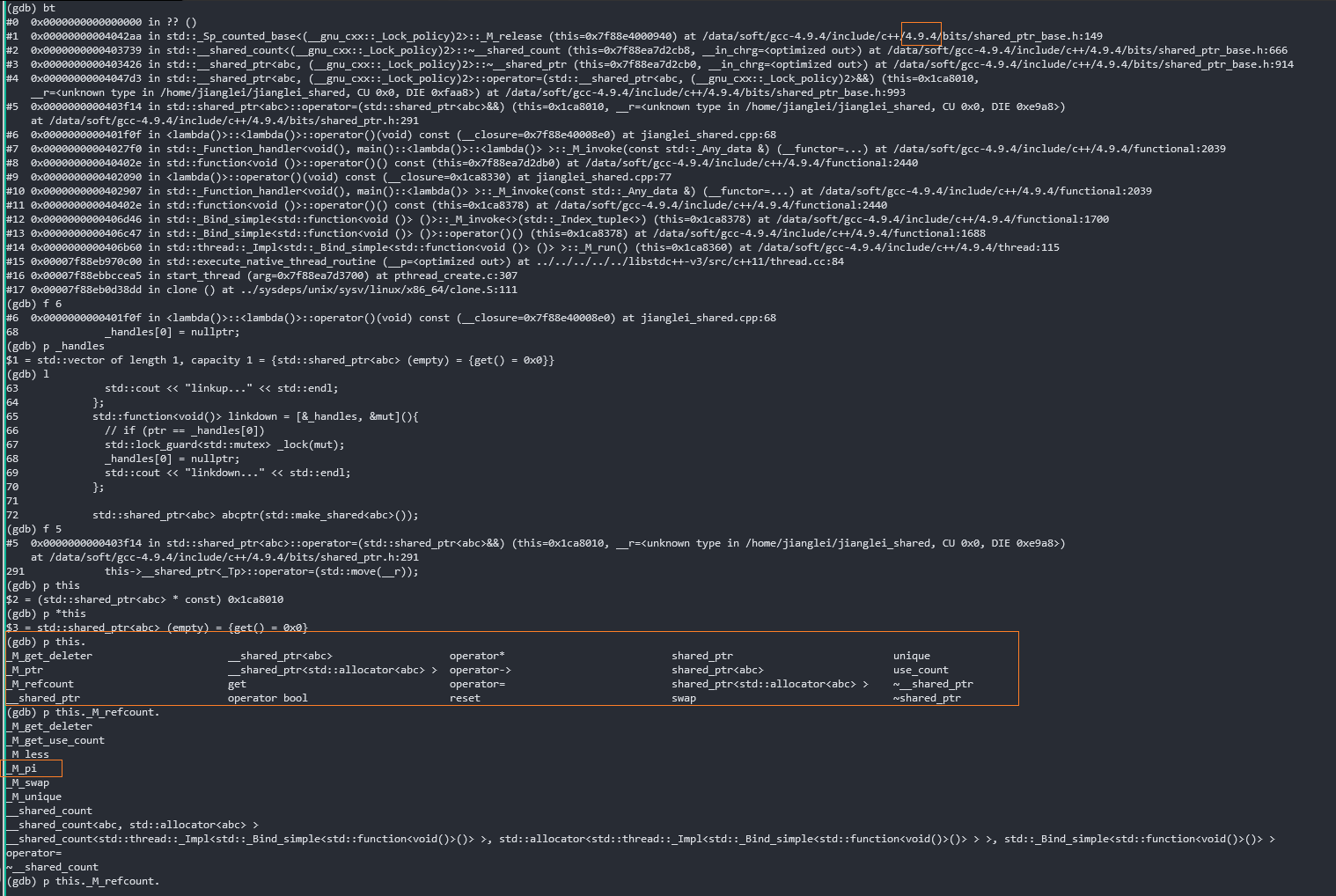
崩溃的地方的大致堆栈(这是测试模拟出的)
讲的很明白的文章
https://cloud.tencent.com/developer/article/1654442
https://www.cnblogs.com/Solstice/archive/2013/01/28/2879366.html
https://www.modernescpp.com/index.php/atomic-smart-pointers
https://www.justsoftwaresolutions.co.uk/threading/why-do-we-need-atomic_shared_ptr.html
源码
最常用的 operator =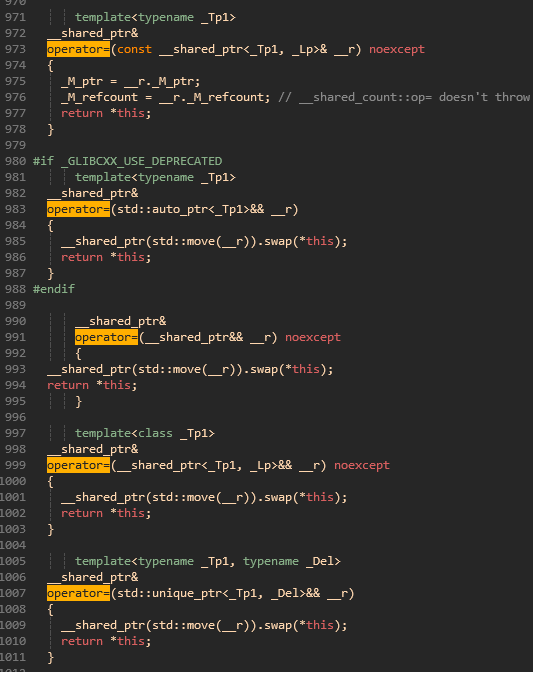
调用的 swap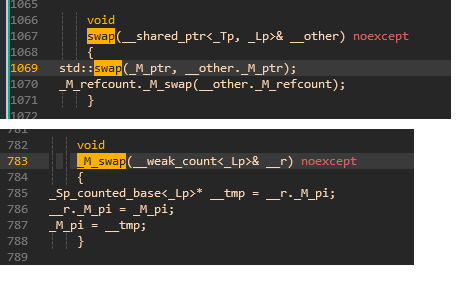
陈硕老师的文章讲的很清楚
陈硕(giantchen_AT_gmail_DOT_com)
2012-01-28
我在《Linux 多线程服务端编程:使用 muduo C++ 网络库》第 1.9 节“再论 shared_ptr 的线程安全”中写道:
(shared_ptr)的引用计数本身是安全且无锁的,但对象的读写则不是,因为 shared_ptr 有两个数据成员,读写操作不能原子化。根据文档(http://www.boost.org/doc/libs/release/libs/smart_ptr/shared_ptr.htm#ThreadSafety), shared_ptr 的线程安全级别和内建类型、标准库容器、std::string 一样,即:
• 一个 shared_ptr 对象实体可被多个线程同时读取(文档例1);
• 两个 shared_ptr 对象实体可以被两个线程同时写入(例2),“析构”算写操作;
• 如果要从多个线程读写同一个 shared_ptr 对象,那么需要加锁(例3~5)。
请注意,以上是 shared_ptr 对象本身的线程安全级别,不是它管理的对象的线程安全级别。
后文(p.18)则介绍如何高效地加锁解锁。本文则具体分析一下为什么“因为 shared_ptr 有两个数据成员,读写操作不能原子化”使得多线程读写同一个 shared_ptr 对象需要加锁。这个在我看来显而易见的结论似乎也有人抱有疑问,那将导致灾难性的后果,值得我写这篇文章。本文以 boost::shared_ptr 为例,与 std::shared_ptr 可能略有区别。
shared_ptr 的数据结构
shared_ptr 是引用计数型(reference counting)智能指针,几乎所有的实现都采用在堆(heap)上放个计数值(count)的办法(除此之外理论上还有用循环链表的办法,不过没有实例)。具体来说,shared_ptr
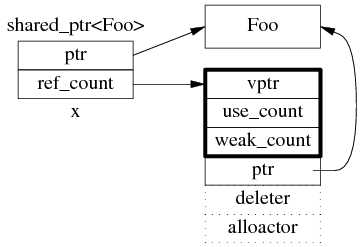
图 1:shared_ptr 的数据结构。
为了简化并突出重点,后文只画出 use_count 的值:
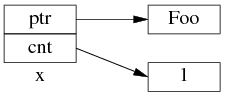
以上是 shared_ptr
如果再执行 shared_ptr
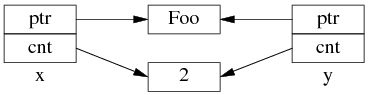
但是 y=x 涉及两个成员的复制,这两步拷贝不会同时(原子)发生。
中间步骤 1,复制 ptr 指针:
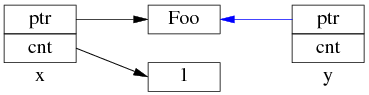
中间步骤 2,复制 ref_count 指针,导致引用计数加 1:
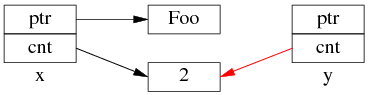
步骤1和步骤2的先后顺序跟实现相关(因此步骤 2 里没有画出 y.ptr 的指向),我见过的都是先1后2。
既然 y=x 有两个步骤,如果没有 mutex 保护,那么在多线程里就有 race condition。
多线程无保护读写 shared_ptr 可能出现的 race condition
考虑一个简单的场景,有 3 个 shared_ptr
shared_ptr
shared_ptr
shared_ptr
一开始,各安其事。

线程 A 执行 x = g; (即 read g),以下完成了步骤 1,还没来及执行步骤 2。这时切换到了 B 线程。

同时编程 B 执行 g = n; (即 write g),两个步骤一起完成了。
先是步骤 1:

再是步骤 2:

这是 Foo1 对象已经销毁,x.ptr 成了空悬指针!
最后回到线程 A,完成步骤 2:

多线程无保护地读写 g,造成了“x 是空悬指针”的后果。这正是多线程读写同一个 shared_ptr 必须加锁的原因。
当然,race condition 远不止这一种,其他线程交织(interweaving)有可能会造成其他错误。
思考,假如 shared_ptr 的 operator= 实现是先复制 ref_count(步骤 2)再复制 ptr(步骤 1),会有哪些 race condition?
杂项
shared_ptr 作为 unordered_map 的 key
如果把 boost::shared_ptr 放到 unordered_set 中,或者用于 unordered_map 的 key,那么要小心 hash table 退化为链表。http://stackoverflow.com/questions/6404765/c-shared-ptr-as-unordered-sets-key/12122314#12122314
直到 Boost 1.47.0 发布之前,unordered_set<std::shared_ptr
Boost 1.51 在 boost/functional/hash/extensions.hpp 中增加了有关重载,现在只要包含这个头文件就能安全高效地使用 unordered_setstd::shared_ptr 了。
这也是 muduo 的 examples/idleconnection 示例要自己定义 hash_value(const boost::shared_ptr
为什么图 1 中的 ref_count 也有指向 Foo 的指针?
shared_ptr
- 无需虚析构;假设 Bar 是 Foo 的基类,但是 Bar 和 Foo 都没有虚析构。
shared_ptr
shared_ptr
sp1.reset(); // 这时 Foo 对象的引用计数降为 1
此后 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo,因为其 ref_count 记住了 Foo 的实际类型。
- shared_ptr
可以指向并安全地管理(析构或防止析构)任何对象;muduo::net::Channel class 的 tie() 函数就使用了这一特性,防止对象过早析构,见书 7.15.3 节。
shared_ptr
shared_ptr
sp1.reset(); // 这时 Foo 对象的引用计数降为 1
此后 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo,不会出现 delete void* 的情况,因为 delete 的是 ref_count.ptr,不是 sp2.ptr。
- 多继承。假设 Bar 是 Foo 的多个基类之一,那么:
shared_ptr
shared_ptr
sp1.reset(); // 此时 Foo 对象的引用计数降为 1
但是 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo,因为 delete 的不是 Bar,而是原来的 Foo。换句话说,sp2.ptr 和 ref_count.ptr 可能具有不同的值(当然它们的类型也不同)。
为什么要尽量使用 make_shared()?
为了节省一次内存分配,原来 shared_ptr
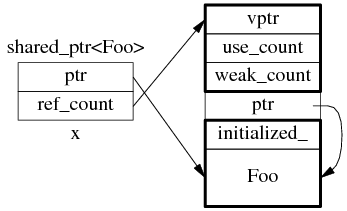
不过 Foo 的构造函数参数要传给 make_shared(),后者再传给 Foo::Foo(),这只有在 C++11 里通过 perfect forwarding 才能完美解决。
(.完.)
测试代码
1 |
|
代码注释 !!!!必要 的地方从上往下分别是:
std::shared_ptr读,引用计数+1std::shared_ptr写,传值为引用,但是原_handles[0]内容被覆盖,保护原对象,加锁std::shared_ptr置空,nullptr也看做是std::shared_ptr,就可以明白,这里也是要加锁的
更好的解决办法
std::atomic_compare_exchange_weakstd::atomic_store
但是