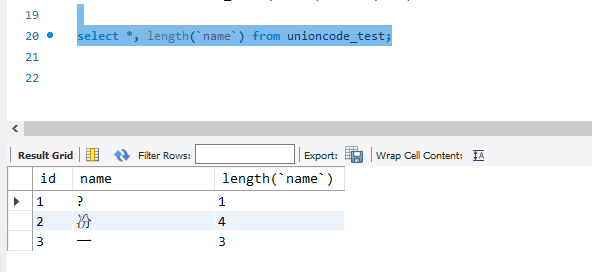
这些是什么?
- ASCII (https://zh.wikipedia.org/wiki/ASCII)
字符编码 - Unicode (https://zh.wikipedia.org/wiki/Unicode)
通用字符集编码 - UTF8 (https://zh.wikipedia.org/wiki/UTF-8)
针对Unicode的可变长度字符编码 - GB2312、GBK、GB18030 (https://zh.wikipedia.org/wiki/GB_18030)
中文编码字符集编码 - Big5 (https://zh.wikipedia.org/wiki/%E5%A4%A7%E4%BA%94%E7%A2%BC)
繁体中文 汉字字符集标准 - 附: CRLF 回车 (CR, ASCII 13, \r) 换行 (LF, ASCII 10, \n)
换行符方式
基础概念
字符:(https://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6_(%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A7%91%E5%AD%A6))字符集:由字符组成的合集,覆盖世界上各个语言的文字,规定了每种文字由那些字符以什么顺序组合出来,并规定了这些字符显示的字形字符编码:(https://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81)
字符集和字符编码
ASCII:这是最基础的字符编码,简单理解可以认为是包含了键盘上的所有字符GB_XXXX:单就我们熟悉的中文,ASCII字符编码一定是不够的,由此GB定义了字符集以及编码方式覆盖了中文文字(也有日韩、emoji等)Unicode:国际通用的字符集编码,覆盖了世界上大部分的文字系统UTF-8:看起来Unicode是最好的解决方式了,那么UTF-8出现和很广泛的使用又是为了什么呢?Unicode:是一个符号集,规定了各种文字符号的代码,为了覆盖这么多文字,Unicode的占用字节数很大,比如ASCII的任意字符,在ASCII里面表示只需要1字节,但是一些中文在Unicode里面需要4字节;Unicode为了统一就把只需要1字节的前面3个字节补0存放;结果就是在计算机资源(存储、带宽)匮乏的年代,Unicode是一种很奢侈的编码方式- 而
UTF-8基于一定的规则,把Unicode从定长编码成变长的,可以使用1-4字节表示一个符号,根据不同的符号变化字节的长度,这样就节省很多的资源占用 UTF-8的规则在ASCII码的范围,用一个字节表示,超出ASCII码的范围就用字节表示,这就形成了我们上面看到的UTF-8的表示方法,这様的好处是当UNICODE文件中只有ASCII码时,存储的文件都为一个字节,所以就是普通的ASCII文件无异,读取的时候也是如此,所以能与以前的ASCII文件兼容。大于ASCII码的,就会由上面的第一字节的前几位表示该unicode字符的长度,比如110xxxxx前三位的二进制表示告诉我们这是个2BYTE的UNICODE字符;1110xxxx是个三位的UNICODE字符,依此类推;xxx的位置由字符编码数的二进制表示的位填入。越靠右的x具有越少的特殊意义。只用最短的那个足够表达一个字符编码数的多字节串。注意在多字节串中,第一个字节的开头”1”的数目就是整个串中字节的数目。
GB_XXXX 和 UTF-8:这里其实更合适的讨论是GB_XXXX 和 Unicode:一个汉字在GB_XXXX编码的值和Unicode里的值是不一样的,而UTF-8只是把Unicode用变长的方式编码出来;所以如果需要从GB_XXXX编码转换到UTF-8是2步操作:1-通过映射表转换到Unicode,2-Unicode用UTF-8做编码
如何区分编码
我们写入一个文件
这是一段中文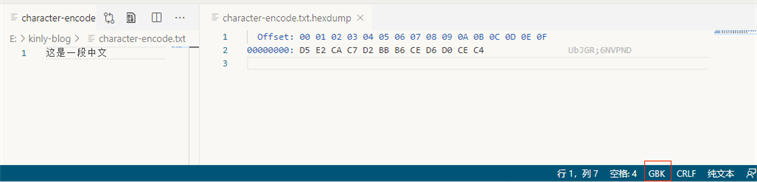
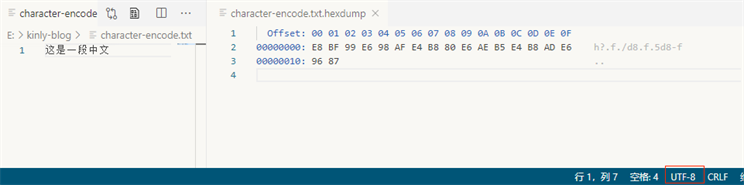
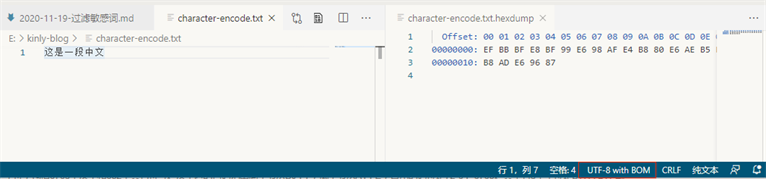
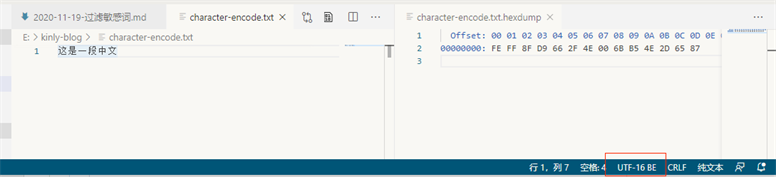
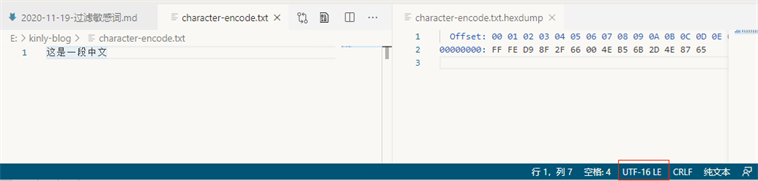
hex 值可以看出,UTF 相关的编码前N个字节,是有一定的规则的 (https://unicode.org/faq/utf_bom.html)
Bytes Encoding Form 00 00 FE FF UTF-32, big-endian FF FE 00 00 UTF-32, little-endian FE FF UTF-16, big-endian FF FE UTF-16, little-endian EF BB BF UTF-8 既然 UTF 编码可以通过前面的字节判断的,那么其他就是GBK编码了(这只是一个简单的编码猜测方式)
做文件GBK-UTF8转换的脚本(自行判断文件编码,并做转换,基于iconv)
1 | !/bin/bash |
附
- BE: big endian
低地址端存放高位字节 - LE: little endian
低地址端存放低位字节
常用编码检查
- shell: file aaa.txt
- IDE: txt、vscode (上图用的就是vscode)
默认编码
- windows: GBK (中文)
- linux: UTF-8
- IDE: VSCode: UTF-8
- 语言: C/C++ 处理的是二进制数据,所以本身是没有默认编码,而编码是跟源文件(代码文件、读取的磁盘文件)
区域设置
既然语言如 C/C++ 处理的是二进制数据(字符集本身是二进制数据的拼合),又有那么多编码并且各个编码所占字节又不同的情况下,我们需要告知程序在做字符转换的时候用那种拆分方式拆分一个字符串数据.
setlocale
告知程序在做多字符-宽字符mbstowcs, wcstombs 互相转换的时候如何解码字符 (需要注意的是这里linux、windows设置是不一样的)linux:(https://man7.org/linux/man-pages/man7/locale.7.html)windows:(https://docs.microsoft.com/en-us/cpp/c-runtime-library/country-region-strings?view=msvc-160)如果你不需要做字符转换(UTF-8 是用途最广的编码方式),只需要保证程序读取的文件都是相同编码(UTF-8)的,如果你的程序里有(比如:中文这种),也需要保证你的源文件是(UTF-8)编码的
未完
C++11
- C++11 新增了字符串的字面量种类
(https://en.cppreference.com/w/cpp/language/string_literal)
(https://en.cppreference.com/w/cpp/language/user_literal)
备忘
** MySQL 的”utf8mb4”才是真正的”UTF-8” **
https://zhuanlan.zhihu.com/p/63360270
1 | drop table if exists unioncode_test; |