前言
- #1. 假设N个人同时从一个地方A下载东西,A的发送流量会暴涨
- #2. 假设A从N处下载一个东西,A的接收流量会暴涨
- 这两种情况都是运营商不愿意看到的,运营商更希望上下行带宽都尽量平稳均匀分配下去
- NAT越来越多主要是Symmetric类型了
- NAT篇 介绍已知Symmetric类型对Port-Restricted-Cone类型很难做到穿透,这造成现在的P2P下载相关越来越少
目标
- 在CDN下载基础上,增加P2P辅助下载,节省CDN成本,也尽量为下载加速
- 基于CDN的下载保持下载压缩文件的方式
相关知识
- CDN服务器已经很便宜了,而且大厂的节点覆盖很广,速度也有保障,但是我们游戏包体超过70G(压缩后40G),即使选择类似带宽峰值的付费方案成本还是很大的
- 最直接的就是加上P2P的下载方式
- 基于google webRTC 音频视频行业的兴起,初看好像这是个做下载器很不错的东西(
只是我自己没做过JS开发,提前就选择放弃了 - torrent已经是很成熟的技术了,在备选列表
- STUN、TURN、ICE 我们只需要P2P的下载,如果NAT无法穿透,走HTTP下载压缩内容就好,TURN、ICE就被排除了,只需要一个侦测IP地址和NAT类型的STUN服务
torrent是否可行?
- torrent 基于一定格式的种子文件,不断请求tracker服务对端列表,尝试穿透下载开始下载
- 对于纯torrent下载的方式是很合适的,想在里面加入混合cdn下载的方式,就比较麻烦了
- 我们自己部署peer也是不可行的,
- 普通服务器的流量、带宽成本是比cdn贵很多的
- 如果不能在网络边缘节点部署torrent-peer,也会导致部分玩家下载速度不稳定或者很慢
- cdn服务器一般都只会开放80的http端口
方向
基于上面的目标:- 玩家机器上是解压过的文件,P2P也就需要传输原始文件(或者分享一方读取原始文件,压缩后传输,接收一方接到压缩内容,解压后写入)
- 为了保证CDN和P2P同时进行,CDN下载压缩内容,写入玩家磁盘需要是已经解压过的内容(在内存解压)
- 下载内容需要
以文件为单位了,无论是CDN的HTTP还是P2P - CDN传输压缩数据,但是写入磁盘需要是以文件为单位的解压后数据,需要研究下怎么能
边下载边解压 - P2P是基于UDP的,不可靠的传输需要在接收一方增加
验证机制,一次传输的限制(MTU)需要一定的验证传输内容和是否接收完成的规则 - 有些游戏单个文件可能会很大,不能是整个文件接收完了再验证,这样很可能导致很大的进度回滚
问题很多,一个个解决吧
HTTP 边下载边解压
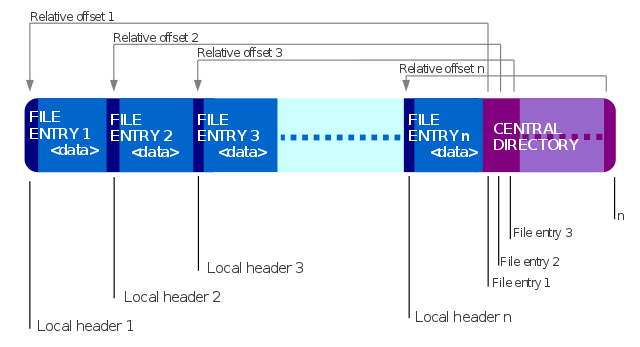
- 压缩文件格式 zip-format
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34//////////////////////////////////////////////////////////////////////////
/*
// https://users.cs.jmu.edu/buchhofp/forensics/formats/pkzip.html
0x0 0x1 0x2 0x3 0x4 0x5 0x6 0x7 0x8 0x9 0xa 0xb 0xc 0xd 0xe 0xf
0x0000 |signature |ver |flag |comp |time |data |crc |
0x0010 |crc |z-size |unz-size |f-n-l |e-f-l |filename
0x0020 (variable size) |
0x0030 |extra field (variable size) |
*/
//////////////////////////////////////////////////////////////////////////
struct local_file_header
{
static constexpr uint32_t _signature = 0x04034b50; // https://stackoverflow.com/questions/50332569/why-i-am-getting-this-error-constexpr-is-not-valid-here
uint16_t _version = 0;
uint16_t _flag = 0;
uint16_t _compression_mod = 0;
uint16_t _mod_time = 0;
uint16_t _mod_date = 0;
uint32_t _crc = 0;
uint32_t _compressed_size = 0;
uint32_t _uncompressed_size = 0;
uint16_t _file_name_len = 0;
uint16_t _extra_field_len = 0;
// variable size (filename)
// variable size (extra field)
};
struct central_directory_header
{
static constexpr uint32_t _signature = 0x02014b50; // https://stackoverflow.com/questions/50332569/why-i-am-getting-this-error-constexpr-is-not-valid-here
// 不处理了,直接返回
}; - 简单点看,zip结构分为3块
- #1.local_file_header
- #2.data
- #3.central_directory_header
- 其中
[#1.local_file_header][#2.data]紧邻,以一个个文件划分 - local_file_header里面也包含file_name、crc、uncompressed_size等信息
- 从上面看问题简单了,只需要参考miniunzip代码,把从磁盘读数据解压换成从网络读数据解压就好了
- 理论上磁盘写入速度是比网络传输快的,所以网络读取开一个socket就好
- 实际操作中遇到的问题:
- #1. miniunzip 代码是依赖central_directory_header解析下载的,但是因为现在读取文件是从网络,不好做到偏移到最后读完central_directory再解析;还好local_file_header里的内容是够用的
- #2. 虽然有zip crc的校验,但是是否真正下载完成还是需要一个文件md5更准确的校验
- #3. 遇到游戏文件更新那种很可能是只下载zip-file某几个文件段,也就是需要提前知道下载那些文件,这些文件在那些zip-file range 段
- #4. 需要标记某个文件正在被HTTP还是P2P下载,并且避免两者重复下载
处理 #1. 按照zip格式和miniunzip代码参考,实现基于local_file_header信息的文件解压处理 #2. 每个文件的文件名和md5单独记录成一个信息文件 .filelist处理 #3. .filelist 文件增加zip_startpos, zip_endpos值标记所在zip文件的绝对位置(包含local_file_header), .filelist文件结构如下1
2
3
4+,(md5),(filename),(zip_pos-start),(zip_pos-end),(zip-size),(unzip-size)
eg.
+,fcf36e5c7b0e345c24539f8dfe5357cb,file_test1.txt,0,108592,108544,648704
+,3b18132de2b0d07cd8d0193cb449e68b,file_test2.txt,0,108592,108544,648704处理 #3.1. http请求分段range的内容,回执会有多余的内容如下,需要单独解析ignore掉1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/*
>> curl http://xxxxx.zip -H "Range: bytes=443079-443083, 11883693-11883697"
--Cdn Cache Server V2.0:0787E385DC32A96203E8A7DCD10E5D99
Content-Type: application/octet-stream
Content-Range: bytes 443079-443083/18670564
PK
--Cdn Cache Server V2.0:0787E385DC32A96203E8A7DCD10E5D99
Content-Type: application/octet-stream
Content-Range: bytes 11883693-11883697/18670564
PK
--Cdn Cache Server V2.0:0787E385DC32A96203E8A7DCD10E5D99--
*/处理 #4. 文件列表顺序是一定的,规定zip从第一个需要下载文件的顺序向后下载,p2p从最后一个需要下载的文件向前下载,并增加内存里文件下载状态的标记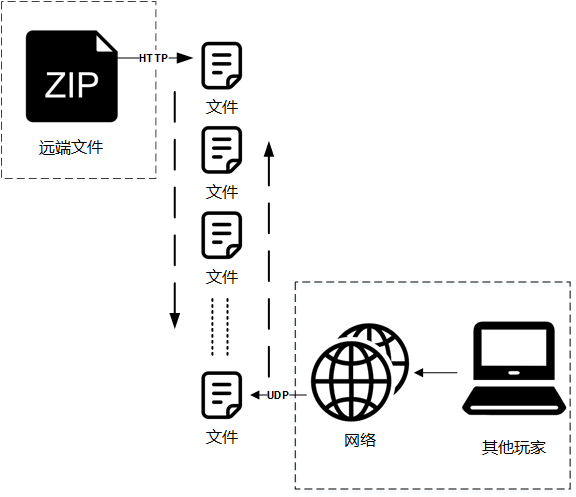
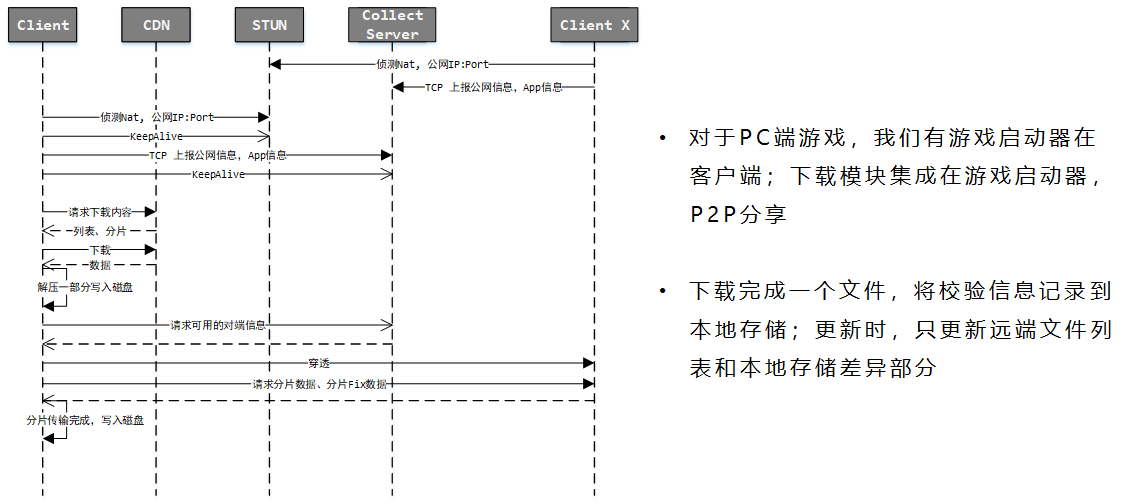
P2P 下载
- P2P NAT 穿透相关知识在这里:NAT篇
- 需要一个STUN-server做客户端网络侦测
- 侦测后上报到一个管理服务器Collect-server做信息收集,并且分发给其他客户端可用的对端信息
- P2P 使用udp协议(因为TCP穿透可能性更小),udp是不可靠传输(是否到达和到达顺序都无法保证),为保证传输稳定,每条消息应尽量保证再一个mtu内
- 另外前面提到了,最好不要整个文件传输完了才校验文件是否正确,尽量在中间就校验
问题和处理方案
- mtu常规(这里只是举例,实际还是在两端穿透之后尝试测试一下mtu最好): 1500 - 20(IP报文) - 16(UDP报文) ~= 1450,自己封包也会占用36个字节左右(protobuffer),然后习惯取整1024,一个数据长度1024,我这里以64个数据长度为一个piece,每个piece都提前计算MD5,然后把这些信息存到 filename.piece 的文件里面。
(64来由:因为这段数据要先存到内存等传输完成算MD5,而且同时可以传之多1024个piece,也就是内存里需要占用约 64M空间,主要是为了避免内存占用过高的问题,决定用64这个数值)1
2
3
4(piece_start),(piece_end),(piece_md5)
eg.
0,65535,a0ce4f802d03c62c762dbc4d58cecd36
65536,131071,b4555bb3dbe47baa2a512da9593652a3 - 上面分片完了,发送端在发送数据的时候也按照这个分片规则,每次传输都带上piece的md5和传输的是64个中的哪一个(shot);接收端收到后就在内存打个piece接收shot的标记,如果这个piece传输完成了,验证一下数据的MD5,通过后写入磁盘,错误的话清掉这个piece,重新请求下载(64KB,影响不大,就全部重新下载吧)
- 发送端收到一个请求后,找到对应的文件,验证文件MD5,如果一致,就从请求的piece+shot偏移位置开始以定长的数据长度传输数据,每个数据传输1次,数据没有发送成功需要重新发的话依靠其他消息单独发。
- torrent 是把文件分成N个没有关系的小块,然后收到那一块填那一块,直到完成
- kcp 的快速重传概念是
发送端发送了1,2,3,4,5几个包,然后收到远端的ACK: 1, 3, 4, 5,当收到ACK3时,KCP知道2被跳过1次,收到ACK4时,知道2被跳过了2次,此时可以认为2号丢失,不用等超时,直接重传2号包,大大改善了丢包时的传输速度。 - 在下载器这个功能上看,torrent/kcp属于两个极端;既然上面都以piece为单位了,那么这里的处理办法是如果前一个piece没有完成,收到了后一个piece的数据,就把前一个piece缺失的shot重新请求一遍;避免piece一直完不成,也避免带宽占用过满
整体
附
- zip file infos
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
if [ $# != 2 ]; then
echo "Usage: ./format_list.sh pak-file list-file"
exit
fi;
function zipinfos()
{
cnt=1;
pos_s=0;
pos_e=0;
for desc in $(zipinfo -sl "$1" | grep -v 'stor' | grep 'defN'); do
unzip_size=`echo $desc | awk -F ' ' '{print $4}'`
zip_size=`echo $desc | awk -F ' ' '{print $6}'`
filename=`echo $desc | awk -F ' ' '{print $10}'`
filename_len=`zipinfo -v "$1" | grep -A 20 "Central directory entry #$cnt:" | grep 'length of filename' | awk -F ' ' '{print $4}'`
extra_len=`zipinfo -v "$1" | grep -A 20 "Central directory entry #$cnt:" | grep 'length of extra field' | awk -F ' ' '{print $5}'`
pos_e=$[$pos_s+zip_size+filename_len+extra_len+30-1]
out="$pos_s,$pos_e,$zip_size,$unzip_size"
pos_s=$[$pos_e+1]
cnt=$[$cnt+1]
echo $out
done
}
last_IFS=$IFS
IFS=$'\n'
zipinfos $1 > format_sub.txt
paste -d, $2 format_sub.txt > format_result.txt
IFS=$last_IFS - file split & piece md5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
if [ $# != 1 ]; then
echo "Usage: ./sss.sh filename"
exit
fi;
function sss()
{
split -b 64k "$1" -d -a 10 ssssss
}
function get_md5()
{
pos_s=0;
for ffm5 in $(find "$1" -name 'ssssss*' | sort | xargs md5sum); do
fname=`echo "$ffm5" | awk -F ' ' '{print $2}'`
fmd5=`echo $ffm5 | awk -F ' ' '{print $1}'`
sz=`ls -l $fname | awk '{print $5}'`
pos_e=$[$pos_s+$sz-1]
out="$pos_s,$pos_e,$fmd5"
pos_s=$[$pos_e+1]
echo $out | sed "s/.\///g"
done
find "$1" -name 'ssssss*' -exec rm -f {} \;
}
function to_file()
{
mkdir -p file_result
for ff in $(find "$1" -type f); do
var=$ff
dir_name=`echo ${var%/*}`
file_name=`echo ${var##*/}`
dir_name=`echo file_result/$dir_name | sed "s/\.\.\///g"`;
# echo $dir_name;
mkdir -p $dir_name
sss $var
get_md5 . > $dir_name/$file_name.piece
done
}
last_IFS=$IFS
IFS=$'\n'
to_file $1
cd file_result
for ff in $(find . -type f); do filename=`echo $ff | sed 's/\.\///g'`; echo "./tool.sh -putfile $filename npl-download-inner -key $filename -replace true"; done > ../upload_doing.sh
zip -rq file_result.zip file_result/
# tar zcf file_result.tar.gz file_result
IFS=$last_IFS