前言
protobuf 基本是 IDL(interface description language) 最常用的序列化/反序列化组件了
2 VS 3
- 默认值:
proto2使用default明确指明默认值;proto3不允许自定义默认值,所有字段都有零默认值 - 语法 :
proto3去掉了required,optional也不需要了 - 枚举 :
proto3需要一个具有 0 的 enums 作为默认值,会多一个UNRECOGNIZED用作没有覆盖的条目;proto2用第一个作为默认值; - UTF8 : string 字段
proto3会强校验 utf8 编码
scalar value types
https://developers.google.com/protocol-buffers/docs/proto3#scalar
| proto Type | Notes | C++ Type | Java/Kotlin Type[1] | Python Type[3] | Go Type | Ruby Type | C# Type | PHP Type | Dart Type |
|---|---|---|---|---|---|---|---|---|---|
| double | double | double | float | float64 | Float | double | float | double | |
| float | float | float | float | float32 | Float | float | float | double | |
| int32 | Uses variable-length encoding. Inefficient for encoding negative numbers – if your field is likely to have negative values, use sint32 instead. | int32 | int | int | int32 | Fixnum or Bignum (as required) | int | integer | int |
| int64 | Uses variable-length encoding. Inefficient for encoding negative numbers – if your field is likely to have negative values, use sint64 instead. | int64 | long | int/long[4] | int64 | Bignum | long | integer/string[6] | Int64 |
| uint32 | Uses variable-length encoding. | uint32 | int[2] | int/long[4] | uint32 | Fixnum or Bignum (as required) | uint | integer | int |
| uint64 | Uses variable-length encoding. | uint64 | long[2] | int/long[4] | uint64 | Bignum | ulong | integer/string[6] | Int64 |
| sint32 | Uses variable-length encoding. Signed int value. These more efficiently encode negative numbers than regular int32s. | int32 | int | int | int32 | Fixnum or Bignum (as required) | int | integer | int |
| sint64 | Uses variable-length encoding. Signed int value. These more efficiently encode negative numbers than regular int64s. | int64 | long | int/long[4] | int64 | Bignum | long | integer/string[6] | Int64 |
| fixed32 | Always four bytes. More efficient than uint32 if values are often greater than 228. | uint32 | int[2] | int/long[4] | uint32 | Fixnum or Bignum (as required) | uint | integer | int |
| fixed64 | Always eight bytes. More efficient than uint64 if values are often greater than 256. | uint64 | long[2] | int/long[4] | uint64 | Bignum | ulong | integer/string[6] | Int64 |
| sfixed32 | Always four bytes. | int32 | int | int | int32 | Fixnum or Bignum (as required) | int | integer | int |
| sfixed64 | Always eight bytes. | int64 | long | int/long[4] | int64 | Bignum | long | integer/string[6] | Int64 |
| bool | bool | boolean | bool | bool | TrueClass/FalseClass | bool | boolean | bool | |
| string | A string must always contain UTF-8 encoded or 7-bit ASCII text, and cannot be longer than 232. | string | String | str/unicode[5] | string | String (UTF-8) | string | string | String |
| bytes | May contain any arbitrary sequence of bytes no longer than 232. | string | ByteString | str (Python 2) | bytes (Python 3) | []byte | String (ASCII-8BIT) | ByteString | string |
default values
- string: empty string
- bytes: empty bytes
- bool: false
- numeric: 0
- enum: the default value is the first defined enum value, which must be 0
numerical 类型序列化
| 编码方式 | key(Type) | 覆盖类型 |
|---|---|---|
| varint | 0 | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 64-bit (8字节) | 1 | fixed64, sfixed64, double |
| 32-bit (4字节) | 5 | fixed32, sfixed32, float |
| – length delimited | 2 | string, bytes, enbedded messaged, packed repeated fields |
| – start group | 3 | groups |
| – end group | 4 | groups |
varint 编码
简单点说就是数值越小的数字使用的字节数越少;最高位表示编码是否继续,如果该位为1,表示接下来的字节仍然是该数字的一部分,如果该位为0,表示编码结束。字节里的其余7位用原码补齐,采用低位字节补齐到高位的办法64-bit / 32-bit 是固定字节数
1 | syntax = "proto3"; |
运行一段小程序,对比 int32 & sint32
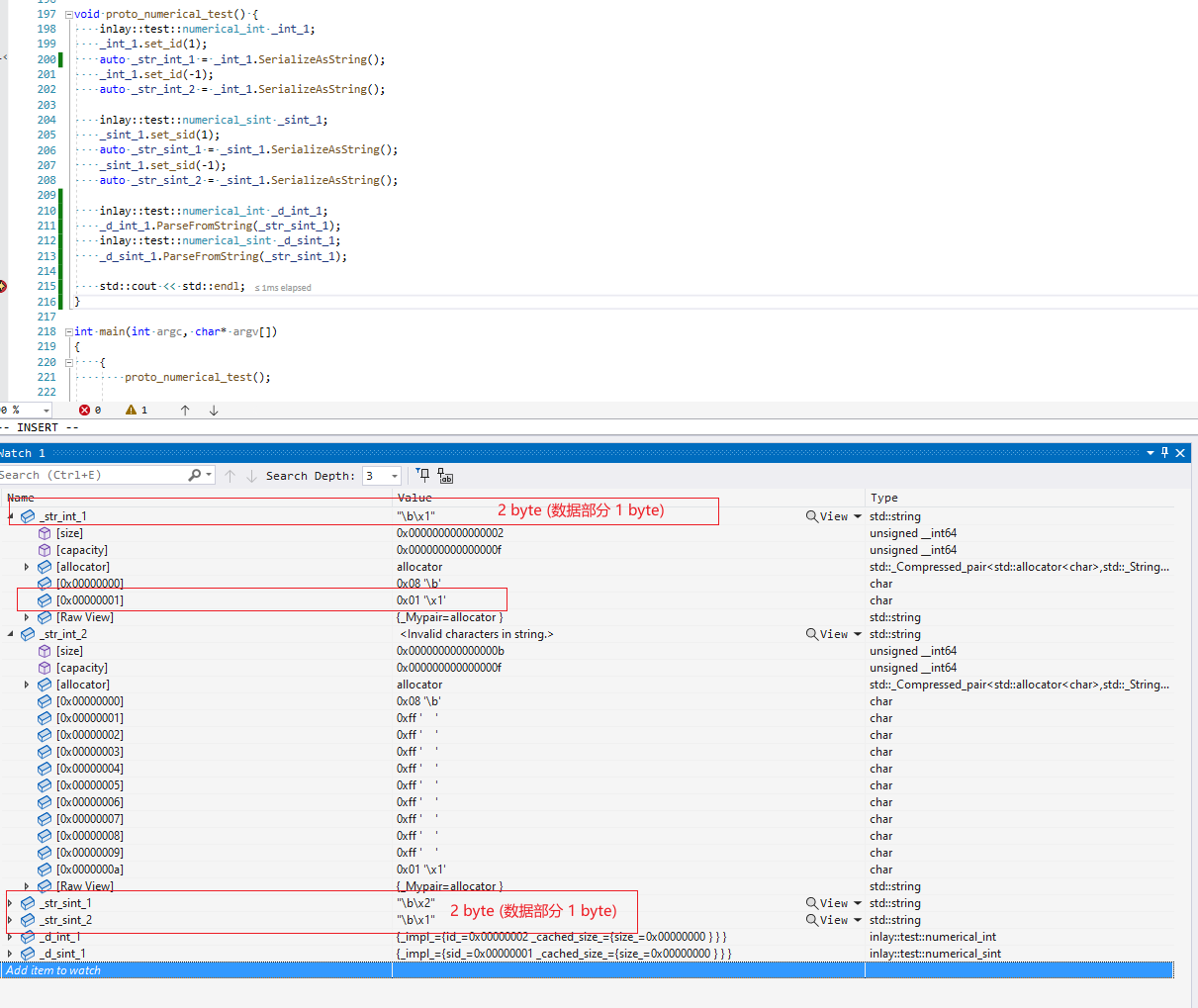
int32 负值数据部分占了10个字节的
对于负数 (高位 1), 大于 1 << 28 的大数 (高位有部分bit被占用),varint会额外多占空间,protobuf 分别用 sint & fixed 类型处理这个问题
sint32 是为负值做优化 zigZag 编码 (将有符号数统一映射到无符号数的一种编码方案)
sint32 因为是映射的zigZag编码方式,是不能和 int32 互转的,例如上面 sint32 里面 1 映射的值实际是 2
fixed32 和 int32
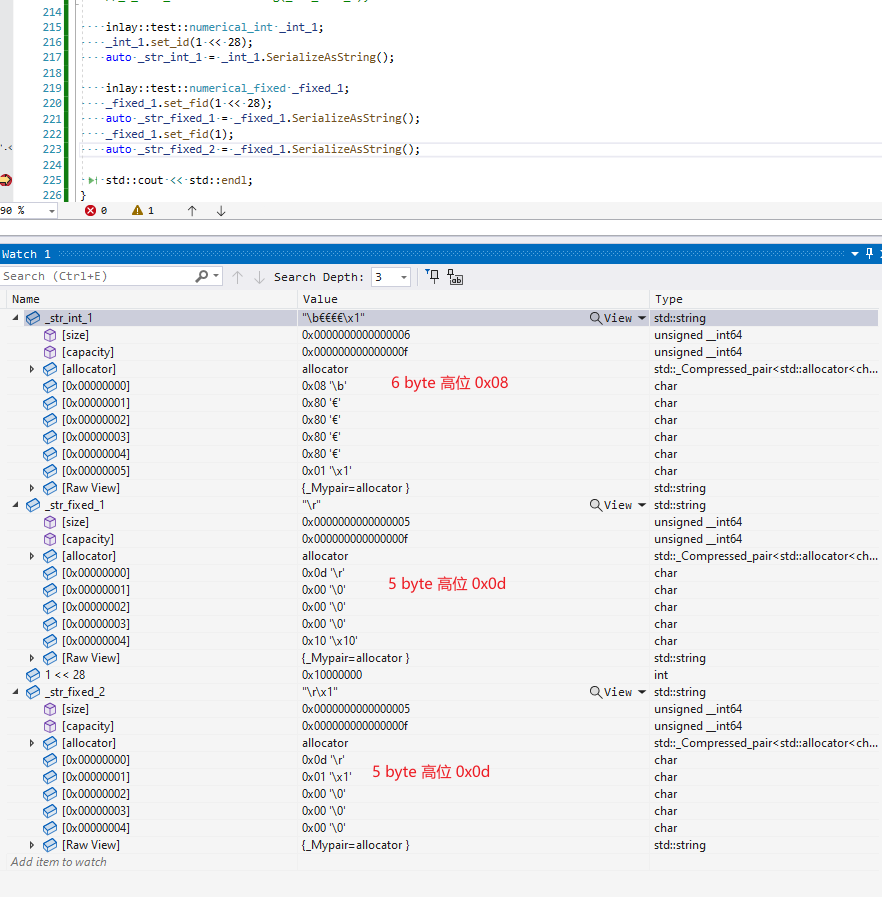
fixed32 数据部分是固定 4 字节的(即使实际数据是 1,也是需要 4 字节的),相比 int32, 对于大数值(超过 1 << 28)可以比 varint 编码方式少 1 byte
fixed32 的前缀是 0x0d (1 << 3 | 5) 这里的 5 表示 numerical 编码方式对应的 key(Type) = 5
int32 的前缀是 0x08 (1 << 3 | 0); 由于 int32 & sint32 的编码方式占位是一样的,但实际上用的又是两种,这里对于 int32 & sint32 的互转是会出错的…
string/bytes 类型序列化
- string & bytes 的序列化规则是一样的:(1 << 3 | 2) + varint(length) + value
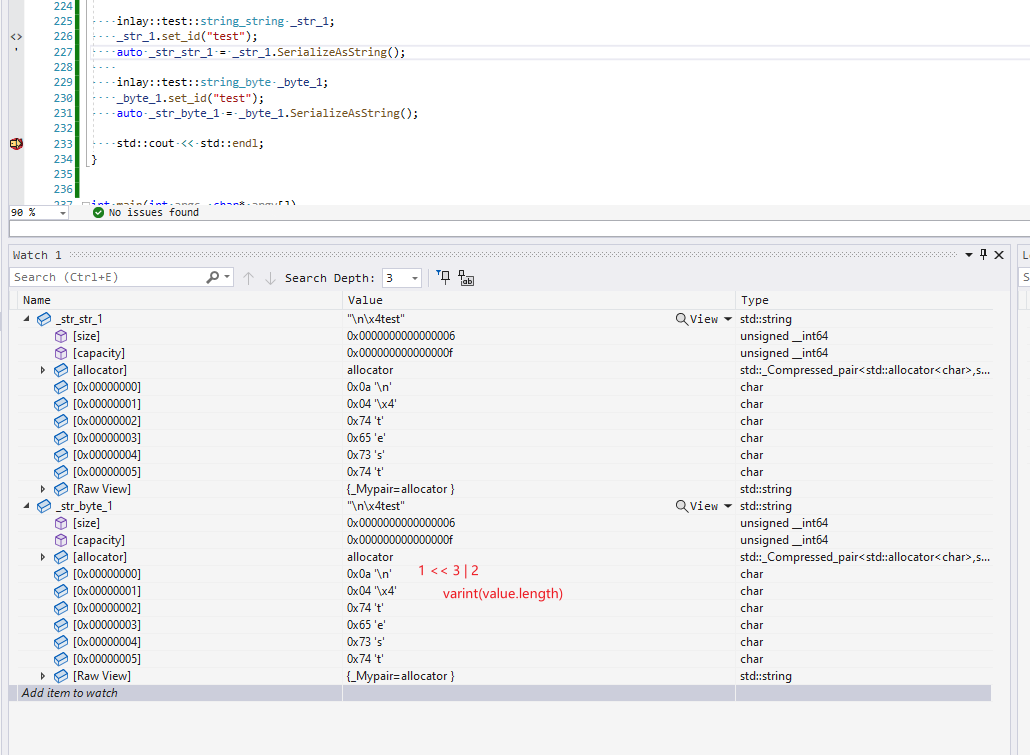
- string 会强制检查value 是否是 utf-8 编码,bytes 是 memcpy 的