性能之巅
时间单位:
| 单位 | 简写 | 与1秒比例 |
|---|---|---|
| 分 | m | $$ 60 $$ |
| 秒 | m | $$ 1 $$ |
| 毫秒 | ms | $$ 0.001 \iff 1/1000 \iff 1 * 10^{-3} $$ |
| 微秒 | us | $$ 0.000001 \iff 1/1000000 \iff 1 * 10^{-6} $$ |
| 纳秒 | ns | $$ 0.000000001 \iff 1/1000000000 \iff 1 * 10^{-9} $$ |
| 皮秒 | ps | $$ 0.000000000001 \iff 1/1000000000 \iff 1 * 10^{-12} $$ |
系统的各种延时:
| 事件 | 延迟 | 相对事件比例 |
|---|---|---|
| 1个CPU周期 | 0.3 ns | 1 s |
| L1 缓存访问 | 0.9 ns | 3 s |
| L2 缓存访问 | 2.8 ns | 9 s |
| L3 缓存访问 | 12.9 ns | 43 s |
| 主存访问(从CPU访问DRAM) | 120 ns | 6 分 |
| 固态硬盘I/O(闪存) | 50-150 us | 2-6 天 |
| 旋转磁盘I/O | 1-10 ms | 1-12 月 |
| 互联网:从旧金山到纽约 | 40 ms | 4 年 |
| 互联网:从旧金山到英国 | 81 ms | 8 年 |
| 互联网:从旧金山到澳大利亚 | 183 ms | 19 年 |
| TCP 包重传 | 1-3 s | 105-317 年 |
| OS 虚拟化系统重启 | 4 s | 423 年 |
| SCSI 命令超时 | 30 s | 3 千年 |
| 硬件虚拟化系统重启 | 40 s | 4 千年 |
| 物理系统重启 | 5 m | 32 千年 |
物理距离->网速基准值推算公式:
- 光速:299792458 m/s -> 300000 km/s
- 光纤是经物理介质的,理论值会比光经空气慢;一般简化用 200000 km/s 为参考
- eg.
新加坡 - 美弗吉尼亚物理距离: 15000 km;单程时间:15000 / 200000 * 1000 = 75 ms;RTT(ping)约 150 ms
术语:
IOPS:每秒发生的输入/输出操作的次数,是数据传说的一个对量方法。对于磁盘的读写,IOPS指的是每秒读和写的次数。吞吐量:评价工作执行的速率,尤其是在数据传输方面,这个属于用于描述数据传输速度(字节/秒或者比特/秒)。再某些情况下(如数据库),吞吐量指的是操作的速度(每秒操作数或每秒业务数)相应时间:一次操作完成的时间。包括用于等待和服务的时间,也包括用来返回结果的时间。延时:延时是描述操作里用来等待服务的时间。再某些情况下,它可以指的是整个操作时间,等同于响应时间。使用率:对于服务所请求的资源,使用率描述再所给定的时间区间内资源的繁忙程度。对于存储资源来说,使用率指的就是所消耗的存储容量(例如,内存使用率)。饱和度:指的是某一资源无法满足服务的排队工作量。瓶颈:在系统性能里,瓶颈指的是限制系统性能的那个资源。分辨和移除系统瓶颈是系统性能的一项重要工作。工作负载:系统的输入或者是对系统所时间的负载叫做工作负载。对于数据库来说,工作负载就是客户端发出的数据库请求和命令。缓存:用于复制或者缓冲一定量数据的高速存储区域,目的是为了避免对较慢的存储层级的直接访问,从而提高性能。出于经济考虑,缓存区的容量要比更慢以及的存储容量要小。
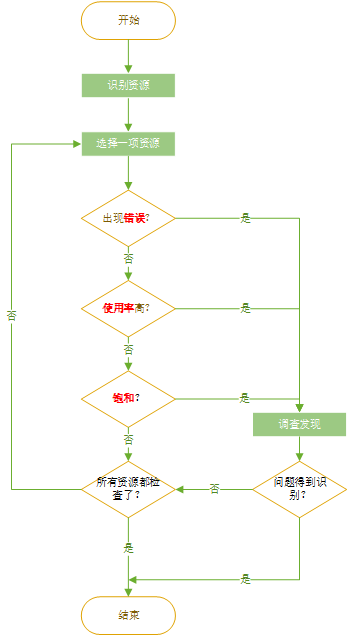
性能分析方法:USE (utilization, saturation, errors)
对于所有的资源,查看它的使用率、饱和度和错误
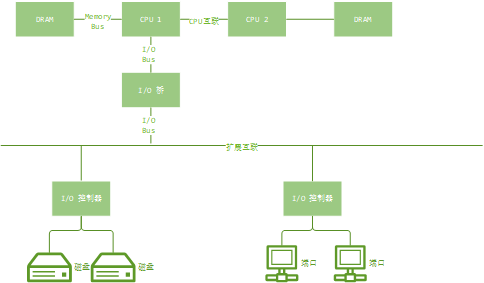
资源:所有服务器物理元器件(CPU、总线…)。某些软件资源也能算在内 (CPU)使用率:在规定的时间间隔内,资源用于服务工作的时间百分比。(单个CPU运行在90%的使用率上)饱和度:资源不能在服务更多额外工作的程度,通常有等待队列。(CPU的平均运行队列长度是4)错误:错误事件的个数。(这个网络接口发生了50次timeout)
过程:
软件资源:
互斥锁:锁被持有的时间是使用时间,饱和度指的是有线程排队在等锁线程池:线程忙于处理工作的时间是使用时间,饱和度指的是等待线程池服务的任务数目进程/线程容量:系统的进程/线程的总数是有上限的,当前的使用数目是使用率,等待分配认为是饱和度,错误是分配失败(cannot fork)文件描述符容量:同进程/线程容量一样,只不过针对的是文件描述符
建议:
对于使用上述这些指标类型,这里有一些总体的建议。
使用率:100%的使用率通常是瓶颈的信号(检查饱和度并确认其影啊)。使用率超过60%可能会是问题,基于以下理由:时间间隔的均值,可能掩盖了100%使用率的短期爆发,另外,一些资源,诸如硬盘(不是 CPU),通常在操作期间是不能被中断的,即使做的是优先级较高的工作。随着使用率的上升,排队延时会变得更颜緊和明显。饱和度:任何程度的饱和都是问题(非零)。饱和程度可以用排队长度或者排队所花的时间来度量。错误:错误都是值得研究的,尤其是随看错误增加性能会变差的那些错误。
操作系统
- 内核:内核执行,时钟周期,内核态/用户态
- 栈:用户栈和内核栈
- 中断和中断线程
- 中断优先级
- 进程:进程创建,进程的生命周期,进程环境
- 系统调用
- 虚拟内存
- 内存管理
- 调度器
- 文件系统:VFS, I/O 栈
- 缓存(括号内表示例子):
- 应用程序缓存
- 服务器缓存(Apache缓存)
- 缓存服务器(Redis缓存)
- 数据库缓存(MySQL缓冲区高速缓存)
- 目录缓存(DNLC)
- 文件元数据缓存(inode缓存)
- 操作系统缓冲区高速缓存(segvn)
- 文件系统主缓存(ZFS ARC)
- 文件系统次级缓存(ZFS L2ARC)
- 设备缓存(ZFS vdev)
- 块缓存(缓冲区高速缓存)
- 磁盘控制器缓存(RAID卡缓存)
- 存储阵列缓存
- 磁盘内置缓存
- 网络
- 设备驱动
- 多处理器:CPU 交叉调用
- 抢占 / 非抢占
- 资源管理
- 观测性
linux 内核功能:
CPU 调度级别:各种先进的CPU调度算法,包括调度域,对于非一致性存储访问架构(NUMA)能做出更好的决策I/O 调度级别:开发了不同的块I/O调度算法,包括deadline、anticipatory和完全公平队列(CFQ)TCP 拥塞:linux内核支持更新的TCP拥塞算法,允许按需选择 net.ipv4.tcp_congestion_control。此外还有很多对TCP的增强Overcommit:有out-of-memory(OOM) killer, 该策略用较少内存做更多的事情Futex:fast user-space mutex 的缩写,用于提供高性能的用户级别的同步原语巨型页:由内核和内存管理单元(MMU)支持的大型内存的预分配Oprofile:研究CPU使用和其他活动的系统剖析工具,内核和应用程序都适用RCU:内核所提供的只读的更新同步机制,支持伴随更新的多个读取的并发,提升了读取频繁的数据和性能和扩展性epoll:可以高效的对多个打开的文件描述符做I/O等待的系统调用,提升了服务器应用的性能模块I/O调度:linux对调度块设备I/O提供可插拔的调度算法DebugFS:一个简单的非结构化接口,用该接口内核可以降数据暴露到用户级别,通常为某些性能工具所用Cpusets:进程独占的CPU分组自愿内核抢占:这个抢占过程,提供了低延时的调度,并且避免了完全抢占的复杂性inotify:文件系统事件的监控框架blktrace:跟踪块I/O事件的框架和工具(后来迁移到了tracepoints中)splice:一个系统调用,将数据在文件描述符和管道之间快速移动,而不用经过用户空间延时审计:跟踪每个任务的延时状态IO审计:测量每个进程的各种存储I/O统计DynTicks:动态的tick,当不需要时(tickless),内核定时中断不会触发,这样可以节省CPU的资源和电力SLUB:新的slab内存分配器的简化版本CFS:完全公平的调度算法cgroups:控制组可以测量并限制进程组的资源使用latencytop:观察操作系统的延时来源的仪器和工具Tracepoints:静态内核跟踪点(也称静态探针)可以组织内核里的逻辑执行点,用于跟踪工具(之前是内核标记)perf:perf是一套性能观测工具,包括CPU性能计数器剖析、静态和动态跟踪透明巨型页:这是一个简化巨型(大型)内存页面使用的框架Uprobes:用户级别软件动态跟踪的基础设施,为其他软件所用(perf、SystemTap等等)KVM:基于内核的虚拟机(Kernel-based Virtual Machine,KVM)使得可以创建虚拟的操作系统实例,并运行虚拟机自己的内核
观测工具:
计数器(默认开启、零开销)
操作系统内核中维护了各种统计数据,称为计数器,用于对事件计数。通常计数器实现为无符号的整形数,发生事件时递增。
系统级别
vmstat:虚拟内存和物理内存统计,系统级别mpstat:每个 CPU 的使用情况iostat:每个磁盘 I /O 的使用情况,由块设备接口报告netstat:网络接口的统计,TCP/IP 栈的统计,以及每个连接的一些统计信息sar:各种各样的统计,能归档历史数据
进程级别(/proc)
ps:进程状态,显示进程的各种统计信息,包括内存和 CPU 使用top:按一个统计数据排序,显示排名高的进程pmap:将进程的内存段和使用统计一起列出
跟踪(默认不开启、有CPU和存储开销)
系统级别
tcpdump:网络包跟踪(libpcap lib)blktrace:块 I/O 跟踪iosnoop:块I/O 跟踪(基于DTrace)exescnoop:跟踪新进程(基于DTrace)dtruss:系统级别的系统调用缓冲跟踪(基于Dtrace)DTrace:跟踪内核的内部活动和所有资源的使用情况,支持静态和动态的跟踪(可编程环境)SystemTap:跟踪内核的内部活动和所有资源的使用情况,支持静态和动态的跟踪(可编程环境)perf:linux 性能事件,跟踪动态和静态的指针
进程级别
strace:系统调用跟踪gdb:源码级别的调试器
剖析
- oprofile:linux系统剖析
- perf:linux性能工具集,包含有剖析的子命令
- DTrace:程序化剖析,基于时间的剖析用自身的profile provider,基于硬件事件的剖析用cpc provider
- SystemTap:程序化剖析,基于时间的剖析用自身的timer tapset,基于硬件事件的剖析用perf tapset
- cachegrind:源自valgrind工具集,能对硬件缓存的使用做剖析,也能用kcachegrind做数据可视化
- Intel VTune Amplifier XE:linux和windows的剖析,拥有包括源代码浏览在内的图形界面
- Oracle Solaris Studio:用自带的性能分析器对Solaris和linux做剖析,拥有包括源代码浏览在内的图形界面
编程语言通常有自己的专用分析器,可以检查语言上下文
监视(sar)
观测来源
| Type | Linux |
|---|---|
| 进程级计数器 | /proc |
| 系统级计数器 | /proc, /sys |
| 设备驱动和调试信息 | /sys |
| 进程级跟踪 | ptrace, uprobes |
| 性能计数器 | perf_event |
| 网络跟踪 | libpcap |
| 进程级延时指标 | 延时核算 |
| 系统级跟踪 | tracepoints, kprobes, ftrace |
/proc
limits:实际的资源限制maps:映射的内存区域sched:CPU调度器的各种统计schedstat:CPU运行时间、延时和时间分片smaps:映射内存区域的使用统计stat:进程状态和统计,包括总的CPU和内存的使用情况statm:以页为单位的内存使用总结status:stat和statm的信息,用户可读task:每个任务的统计目录
系统级别:
cpuinfo:物理处理器信息,包含所有虚拟CPU、型号、时钟频率和缓存大小diskstats:对于所有磁盘设备的磁盘I/O统计interrupts:每个CPU的中断计数器loadavg:负载平均值meminfo:系统内存使用明细net/dev:网络接口统计net/tcp:活跃的TCP套接字信息schedstat:系统级别的CPU调度器统计self:关联当前进程ID路径的符号链接slabinfo:内核slab分配器缓存统计stat:内核和系统资源的统计,包括CPU、磁盘、分页、交换区、进程zoneinfo:内存区信息
/sys
应用程序
目标
延时:低应用响应时间吞吐量:高应用程序操作率或者数据传输率资源使用率:对于给定应用程序工作负载,高效的使用资源
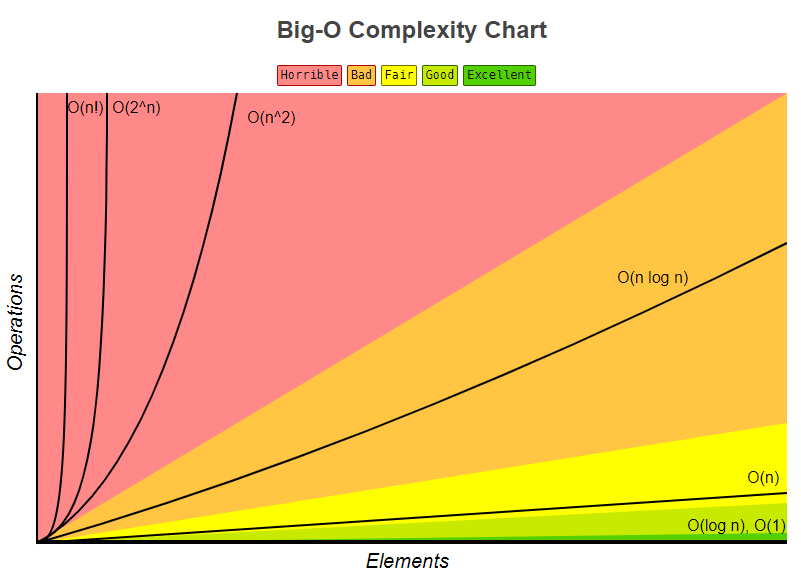
大O标记法
| 标记法 | 举例 |
|---|---|
| O(1) | 布尔判断 |
| O(logn) | 顺序队列的二分搜索 |
| O(n) | 链表的线性搜索 |
| O(nlogn) | 快速排序(一般情况) |
| O(n^2) | 冒泡排序(一般情况) |
| O(2^n) | 分解质因数;指数增长 |
| O(n!) | 旅行商人问题的穷举法 |