说明
线上环境配置:Centos 7.5 3.10.0 2核 4G
游戏上线,其中2组服务器遇到了内存增长异常的问题
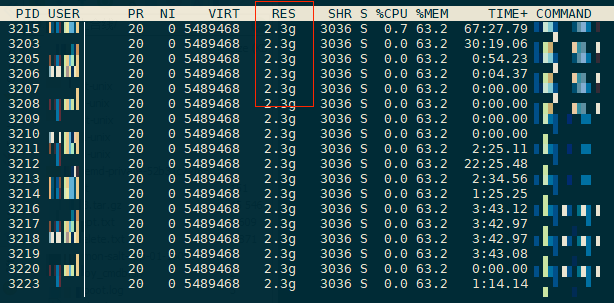
程序内存泄漏?
程序内部对象都是以对象池方式分配的, 唯一malloc的地方是网络buffer缓冲
- grep -rn ‘chunk’ ./* log 目录, 查对象池分配日志
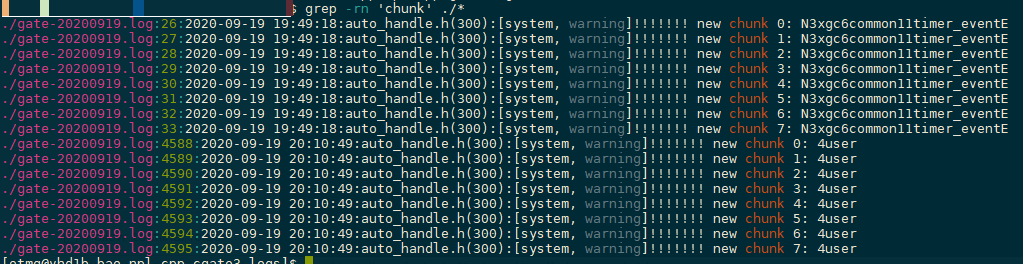
对象池没有新分配的内容这些都是原始的分配,分别是 gate 管理的 user 对象 & timer 定时器对象(1个chunk 1024 个对象) - 涉及malloc free的内存,跟随net session的accept & bedelete

上图指令分别是: accept次数, bedelete次数, 当前连接数socket-session 对象建立,每个session 1M (send-buffer) + 1M (recv-buffer),不是session没有释放导致的 - pmap 看具体占用
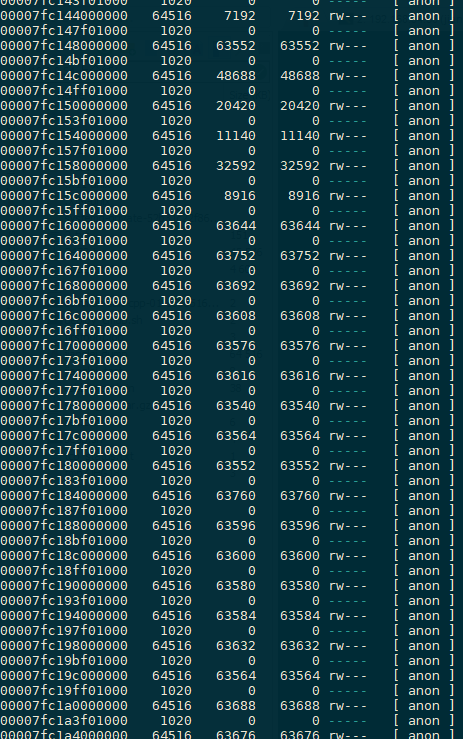
大量没有释放出来的内存 64M
程序是不会分配这么大的内存的,内存分配器是glibc,glibc官方说明Starting with glibc 2.11 (for example, customers upgrading from RHEL 5 to RHEL 6), by default, when glibc malloc detects mutex contention (i.e. concurrent mallocs), then the native malloc heap is broken up into sub-pools called arenas. This is achieved by assigning threads their own memory pools and by avoiding locking in some situations. The amount of additional memory used for the memory pools (if any) can be controlled using the environment variables MALLOC_ARENA_TEST and MALLOC_ARENA_MAX. MALLOC_ARENA_TEST specifies that a test for the number of cores is performed once the number of memory pools reaches this value. MALLOC_ARENA_MAX sets the maximum number of memory pools used, regardless of the number of cores. The default maximum arena size is 1MB on 32-bit and 64MB on 64-bit. The default maximum number of arenas is the number of cores multiplied by 2 for 32-bit and 8 for 64-bit. This can increase fragmentation because the free trees are separate. In principle, the net performance impact should be positive of per thread arenas, but testing different arena numbers and sizes may result in performance improvements depending on your workload. You can revert the arena behavior with the environment variable MALLOC_ARENA_MAX=1
解释: glibc 在多线程竞争malloc时候,会创建新的arena块,一个arena是64M(64位系统上) 截图里面 64516 + 1020 = 65536 64M1
2ldd gate # 查libc.so所在目录 (libc)
/lib64/libc.so.6 # 查版本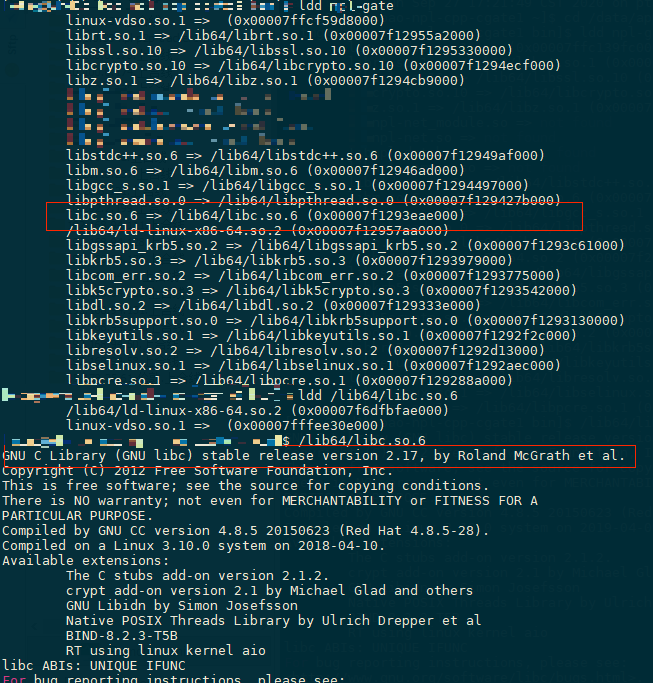
线上只有两组服务器有内存增长过快的问题,是否和系统版本、环境变量有关?
- kernel 确认相同
- 程序使用的环境变量
cat /proc/2948/environ | tr '\000' '\n'基本相同(相差的对内存问题没有关系) - SA 帮忙确认
宿主机内核、glibc版本对内存没有影响
glibc的内存管理
- 内存布局
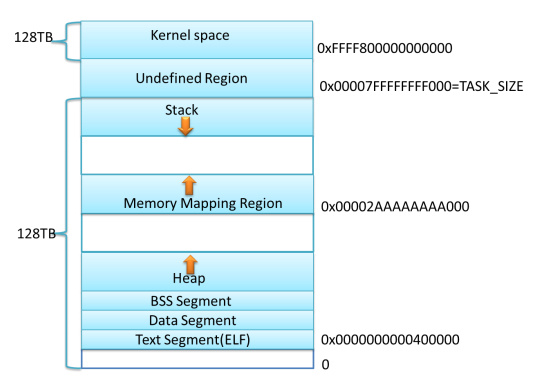
- malloc 内存分配的系统调用
brk() sbrk()
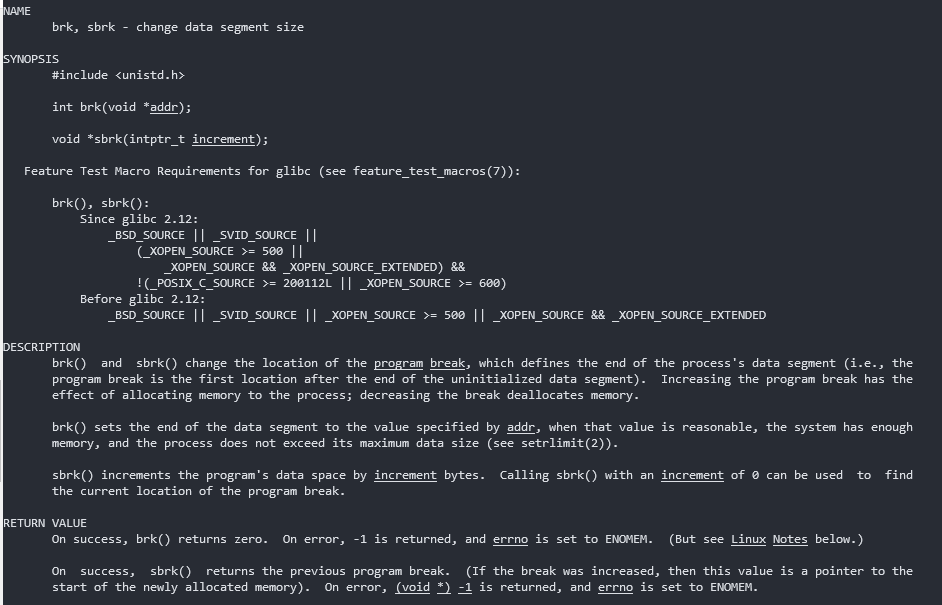
申请heap(移动最高地址指针,性能损耗小)
内存碎片的产生:先申请了10 指针移动到curr += 10, 然后申请20 指针移动到curr += 20; 释放10 当前指针在20位置,20还在使用,无法释放。只有高地址内存释放了,低地址才会释放
为了避免这种内存空洞的产生,在分配>=128K内存的时候glibc使用的是mmap; 由M_MMAP_THRESHOLD调节;M_TRIM_THRESHOLD调节空闲归还mmap() munmap()
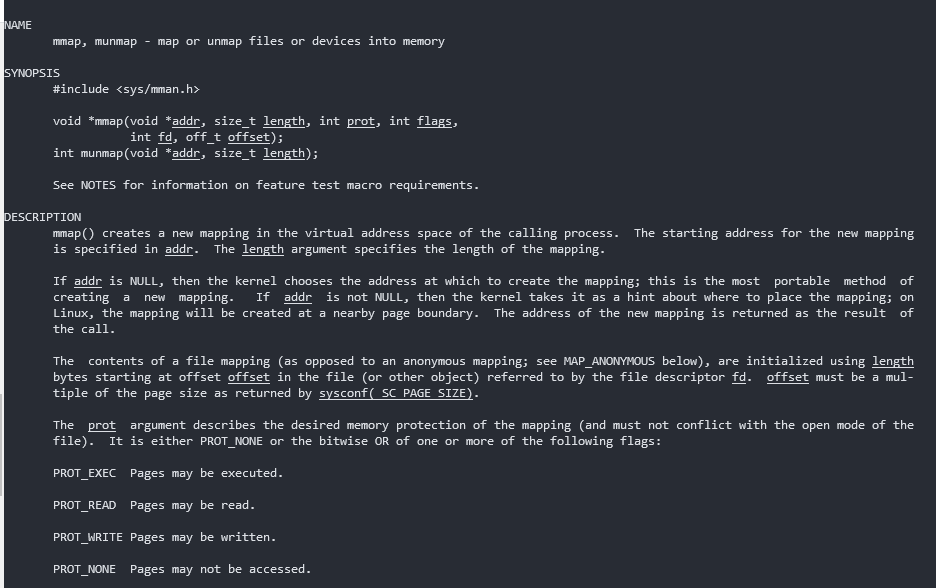
申请memory mapping segment(在虚拟地址空间找空闲的内存,性能损耗稍大)
整页分配,整页释放
但是如果程序使用的都是大内存(>128K),为了避免mmap/munmap带来的性能消耗,常见的设置是
mallopt(M_MMAP_MAX, 0); mallopt(M_TRIM_THRESHOLD, -1);显然这样会带来更大的内存消耗(brk造成的内存空洞)
可用for ((i = 1; i <100; i++)); do ps -o majflt,minflt -C npl-gate; sleep 1; done监测某个程序是否需要这种设置linux内存管理的基本思想: 内存延迟分配,分配的是虚拟内存,只有真正访问的时候才建立虚拟内存和物理内存的映射
- glibc的malloc
size < M_MMAP_THRESHOLD 先尝试从brk已经释放的内存中获取,获取不到,调用sbrk
size >= M_MMAP_THRESHOLD 调用mmapM_MMAP_THRESHOLD default:(128 * 1024) min:(0) max(512 * 1024 or 4 * 1024 * 1024)M_TRIM_THRESHOLD default:(128 * 1024) -1 disables trimming completelymallopt文档 - glibc 内存分配算法
Arena: 管理堆内存链表的; 每个线程有自己的arena区域,arena有上限32-bit: 2 * cores; 64-bit: 8 * cores
当线程数量超过arena上限的时候,多个线程会共享一个arena区域,多线程竞争时加锁处理Chunk: 每次分配的堆内存,会根据需要被分割成>=1的chunkBins: 管理已经被释放的chunk链表- fastbin
- unsorted bin [free’d]
- small bin (2-63) [< 512 bytes]
- large bin (64-126) [>= 512 bytes]
分配策略: fastbin -> unsortedbin -> smallbin -> largebin -> top chunk -> 系统分配,并把多余的内存放回到bins里面释放策略:在释放某个时检查附近的块是不是free的,如果是,那么合并添加到unsortedbin里面
写测试程序测试验证内存分配问题
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
int main() {
int block_size = K;
int block_num = K_NUM;
block_size = M;
block_num = M_NUM;
printf("%s\n", "----- block M");
mallopt(M_MMAP_THRESHOLD, M * 2);
printf("%s\n", "----- glibc mmap threshold");
char *ptrs[K_NUM];
for (int i = 0; i < block_num; ++i)
{
ptrs[i] = (char *)malloc(1 * block_size);
memset(ptrs[i], 0, 1 * block_size);
}
char *tmp1 = (char *)malloc(1);
memset(tmp1, 0, 1);
printf("%s\n", "----- one more 1 malloc");
//malloc_info(0, stdout);
printf("%s\n", "##### malloc done");
getchar();
printf("%s\n", "##### start free memory");
for(int i = 0; i < block_num; ++i) {
free(ptrs[i]);
}
printf("%s\n", "##### free done");
//malloc_info(0, stdout);
getchar();
return 0;
}



1
g++ -g -o memory_test01 -std=c++11 memory_test01.cpp -lpthread -DBLOCK_M
这次编译结果 ./strace -f ./memory_test 可以看到调用都是mmap
1
g++ -g -o memory_test01 -std=c++11 memory_test01.cpp -lpthread -DBLOCK_M -DM_MMAP
这次编译结果 ./strace -f ./memory_test 可以看到调用都是brk
测试2:线程内存分配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
int main() {
std::mutex lock_;
std::vector<char*> ptrs;
std::function<void()> func_create = [&]() {
for (int i = 0; i < MAX_NUM / MAX_THREAD; ++i)
{
std::lock_guard<std::mutex> _lock(lock_);
ptrs.emplace_back((char *)malloc(1 * K));
memset(ptrs.back(), 0, 1 * K);
}
char *tmp1 = (char *)malloc(1);
memset(tmp1, 0, 1);
};
std::vector<std::thread> tasks;
for (int i = 0; i < MAX_THREAD; ++i) {
tasks.push_back(std::thread(func_create));
}
std::for_each(tasks.begin(), tasks.end(), [](std::thread& t){t.join();});
char *tmp1 = (char *)malloc(1);
memset(tmp1, 0, 1);
printf("%s\n", "malloc done");
getchar();
printf("%s\n", "start free memory");
for(int i = 0; i < MAX_NUM; ++i) {
free(ptrs[i]);
}
printf("%s\n", "free done");
getchar();
return 0;
}用测试1类似的办法,可以看到多线程内存的分配和释放
测试3:内存一边分配一边释放,监控内存占用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
typedef void* pvoid_t;
typedef const void* cvoid_t;
class asio_NetBuffer
{
// .... 一个简单的内存管理器
};
struct session
{
asio_NetBuffer _send_buffer;
asio_NetBuffer _recv_buffer;
};
struct NetEvent
{
pvoid_t session;
uint32_t handle;
uint32_t event;
};
struct NetData
{
int32_t length;
};
std::queue< std::tuple< pvoid_t, size_t > > event_queue_;
std::mutex lock_queue_;
char* _1Mdata;
void Push( pvoid_t data, size_t size )
{
std::lock_guard< std::mutex > _lock( lock_queue_ );
event_queue_.push( std::make_tuple( data, size ) );
}
bool Kick( pvoid_t &data, size_t &size )
{
std::lock_guard< std::mutex > _lock( lock_queue_ );
if( event_queue_.empty() )
return false;
auto pkg = event_queue_.front();
data = std::get<0>( pkg );
size = std::get<1>( pkg );
event_queue_.pop();
return true;
}
std::atomic<int> _index;
std::mt19937& get_random_driver()
{
static std::mt19937 mt( (int32_t) time( nullptr ) );
return mt;
}
template < class T1, class T2, typename std::enable_if< !std::is_floating_point< T1 >::value && !std::is_floating_point<T2>::value, bool >::type = true >
auto random_range( T1 Min, T2 Max )->decltype( Min + Max )
{
if( Min == Max )
return Min;
using NewT = decltype( Min + Max );
if( Min > Max )
return std::uniform_int_distribution<NewT>( Max, Min )( get_random_driver() );
else
return std::uniform_int_distribution<NewT>( Min, Max )( get_random_driver() );
}
int main()
{
_1Mdata = (char*)malloc(80 * 1024 * 1024);
memset(_1Mdata, 'a', 80 * 1024 * 1024);
std::function<void()> func_create = [_index](){
std::cout << "thread : "<<std::this_thread::get_id() << std::endl;
session* _ss = new session();
_ss->_send_buffer.open(10 * 10024 * 1024);
_ss->_recv_buffer.open(10 * 10024 * 1024);
int event_id = _index.load();
_index += 1000;
while (true)
{
int packet_length = random_range(10, 80 * 1024 * 1024);
NetEvent evt;
evt.session = nullptr;
evt.handle = 1;
evt.event = event_id++;
NetData dat;
dat.length = packet_length;
asio_NetBuffer packet(NET_PACKET_SIZE(packet_length));
packet.put(&evt, sizeof(evt));
packet.put(&dat, sizeof(dat));
packet.put(_1Mdata, packet_length);
Push(packet.release(), NET_PACKET_SIZE(packet_length));
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
delete _ss;
std::cout << "thread end : " <<std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(30));
};
std::vector<std::thread> tasks;
for (int i = 0; i < MAX_THREAD; ++i) {
tasks.push_back(std::thread(func_create));
}
while (true)
{
pvoid_t data = nullptr;
size_t size = 0;
while (Kick(data, size))
{
NetEvent* pHeader = (NetEvent*)data;
// std::cout << "event:" << pHeader->event << std::endl;
free(data);
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
std::for_each(tasks.begin(), tasks.end(), [](std::thread& t){t.join();});
free(_1Mdata);
MallocExtension::instance()->ReleaseFreeMemory();
std::cout << "threads joined ... " << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(30));
return 0;
}Shell:1
for ((i=1; i<100; i++)); do pmap -x 4454 | grep total; sleep 1; done
RSS在3.5G左右会有一次比较大的空间释放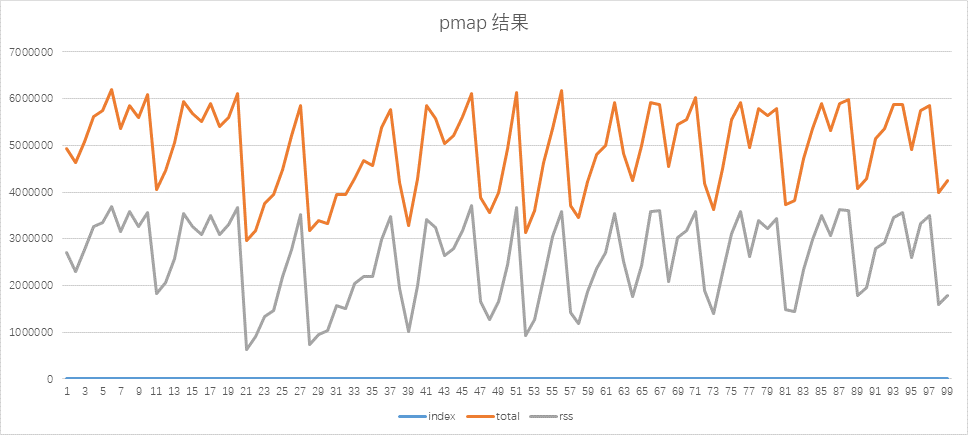
暂时的结果和线上临时处理
暂时的结果
根据上面问题的筛查和测试程序,基本可以确认不是程序内存泄漏
由于程序net代码用的package和event内存都是是每次单独malloc出来的,分配大小比较乱,基本定位大概率是由于这里的使用方式加上内存分配器机制导致的
也在线上没有人的时候gdb attach到进程 dump memory看了其中一块64M的内存,strings结果基本都是网络收发包的文本
理论上这些内存是可以归还给系统的,但是由于增长速度过快,而且还只有2组服务器有这种情况,不敢任由服务器有OOM的风险
线上临时处理
由于开发过程中使用过 tcmalloc + gperftools 查内存问题,稍微看过api,知道有ReleaseFreeMemory的操作,就临时把一台服务器换成了tcmalloc的内存分配器
程序链接 google tcmalloc(介绍) 重新编译
程序新增信号执行 MallocExtension::instance()->ReleaseFreeMemory(),以防万一
记录
线上环境不比测试环境,很多操作都要很小心,特别是长连接的服务器,不敢有过多和长时间的操作
一些内存指令
free1
2
3total used free shared buff/cache available
Mem: 4046216 2444056 238012 194580 1364148 1117984
Swap: 4193276 706248 3487028total: 物理内存总量used: 使用中的内存总量free: 空闲内存总量Buffers/cached: 磁盘缓存的内存量SWAP: 虚拟内存/proc/meminfo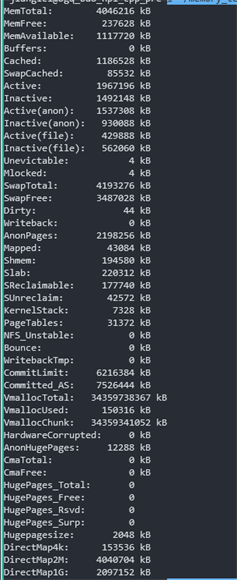
/proc/pid/maps
同 pmap -x pidsar -rsar -B
后续:关于tcmalloc, ptmalloc, jmalloc
目前:
tcmalloc分配内存更快,因为用的大都是sbrk?ptmalloc大内存会用mmap/munmaptcmalloc应该是更占内存的?因为sbrk回收的问题tcmalloc像系统要的内存维护在PageHeap,8K=1page,释放的内存都在FreeList,线程有自己的ThreadCache,但是内存都是从同一地方拿,归还同一地方;内存利用率相对更高?jmallocfacebook推出的, 最早的时候是freebsd的libc malloc实现。 目前在firefox、facebook服务器各种组件中大量使用。
汇总:
-ptmalloc
-ptmalloc有一个主分配区(main arena), 有多个非主分配区。非主分配区只能使用mmap向操作系统批发申请HEAP_MAX_SIZE(64位系统为64MB)大小的虚拟内存。当某个线程调用malloc的时候,会先查看线程私有变量中是否已经存在一个分配区,如果存在则尝试加锁,如果加锁失败则遍历arena链表试图获取一个没加锁的arena, 如果依然获取不到则创建一个新的非主分配区。free()的时候也要获取锁。分配小块内存容易产生碎片,ptmalloc在整理合并的时候也要对arena做加锁操作。在线程多的时候,锁的开销就会增大。
-ptmalloc用户请求分配的内存使用chunk表示, 每个chunk至少需要8个字节额外的开销。用户free掉的内存不会马上归还操作系统,ptmalloc会统一管理heap和mmap区域的空闲chunk,避免了频繁的系统调用。
-ptmalloc将相似大小的 chunk 用双向链表链接起来, 这样的一个链表被称为一个 bin。 Ptmalloc 一共 维护了 128 个 bin,并使用一个数组来存储这些 bin
-ptmalloc数组中的第一个为 unsorted bin, 数组中从 2 开始编号的前 64 个 bin 称为 small bins, 同一个small bin中的chunk具有相同的大小。 small bins后面的bin被称作large bins
-ptmalloc当free一个chunk并放入bin的时候, 还会检查它前后的chunk 是否也是空闲的, 如果是的话, 会首先把它们合并为一个大的chunk, 然后将合并后的chunk 放到unstored bin中。另外为了提高分配的速度,会把一些小的(不大于64B) chunk先放到一个叫做 fast bins 的容器内。
-ptmalloc在fast bins和bins都不能满足需求后,会设法在一个叫做top chunk的空间分配内存。对于非主分配区会预先通过mmap分配一大块内存作为top chunk, 当bins和fast bins都不能满足分配需要的时候, c会设法在top chunk中分出一块内存给用户, 如果top chunk本身不够大, 分配程序会重新mmap分配一块内存chunk, 并将top chunk 迁移到新的chunk上,并用单链表链接起来。如果free()的chunk恰好 与 top chunk 相邻,那么这两个 chunk 就会合并成新的 top chunk,如果top chunk大小大于某个阈值才还给操作系统。主分配区类似,不过通过sbrk()分配和调整top chunk的大小,只有heap顶部连续内存空闲超过阈值的时候才能回收内存
-ptmalloc需要分配的 chunk 足够大,而且 fast bins 和 bins 都不能满足要求,甚至 top chunk 本身也不能满足分配需求时, 会使用 mmap 来直接使用内存映射来将页映射到进程空间
-ptmalloc缺陷后分配的内存先释放,因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
-ptmalloc缺陷多线程锁开销大, 需要避免多线程频繁分配释放。
-ptmalloc缺陷内存从thread的areana中分配, 内存不能从一个arena移动到另一个arena, 就是说如果多线程使用内存不均衡,容易导致内存的浪费。比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena, 但是线程1的300M却不能用了。
-ptmalloc缺陷每个chunk至少8字节的开销很大
-ptmalloc缺陷不定期分配长生命周期的内存容易造成内存碎片,不利于回收。 64位系统最好分配32M以上内存,这是使用mmap的阈值
-ptmalloc使用经验避免多线程频繁分配和释放内存,会造成频繁加解锁。
-ptmalloc使用经验不要分配长生命周期的内存块,容易造成内碎片,影响内存回收。
-ptmalloc使用经验对于动态增长STL容器,要注意它维护的队列却是分配在heap上的。也就是说一个这样的临时对象所操作过的内存,依然可能产生碎片。如果这样的函数被频繁调用,碎片就会非常多。尽量成批reserve一块内存使用。减少在容器已满的情况下仍然push_back单个元素的操作,这样非常容易产生碎片。
-ptmalloc使用经验即便我们做过shrink_to_fit的工作(std::vector<t*>(v).swap(v)),如果里面是碎片,那也会被驻留在brk维护的free_list中,不会被释放。
-ptmalloc使用经验长时间的线上服务更应该注重编码习惯,尽量减少内存碎片。
-ptmalloc使用经验每个线程至少有一个,至多有cores_num*8个自己的arena(看成by线程的内存池),减少锁的使用。不同arena之间不能交替使用。多尝试arena数目的设置,对虚拟内存的消耗有挺大的影响。tcmalloctcmalloc为每个线程分配了一个线程本地ThreadCache,小内存从ThreadCache分配,此外还有个中央堆(CentralCache),ThreadCache不够用的时候,会从CentralCache中获取空间放到ThreadCache中。tcmalloc小对象(<=32K)从ThreadCache分配,大对象从CentralCache分配。大对象分配的空间都是4k页面对齐的,多个pages也能切割成多个小对象划分到ThreadCache中tcmalloc小对象有将近170个不同的大小分类(class),每个class有个该大小内存块的FreeList单链表,分配的时候先找到best fit的class,然后无锁的获取该链表首元素返回。如果链表中无空间了,则到CentralCache中划分几个页面并切割成该class的大小,放入链表中tcmalloc大对象(>32K)先4k对齐后,从CentralCache中分配。 CentralCache维护的PageHeap数组中第256个元素是所有大于255个页面都挂到该链表中tcmalloc当best fit的页面链表中没有空闲空间时,则一直往更大的页面空间则,如果所有256个链表遍历后依然没有成功分配。则使用sbrk, mmap, /dev/mem从系统中分配。tcmallocPageHeap管理的连续的页面被称为span. 如果span未分配, 则span是PageHeap中的一个链表元素. 如果span已经分配,它可能是返回给应用程序的大对象, 或者已经被切割成多小对象,该小对象的size-class会被记录在span中tcmalloc在32位系统中,使用一个中央数组(central array)映射了页面和span对应关系, 数组索引号是页面号,数组元素是页面所在的span。在64位系统中,使用一个3-level radix tree记录了该映射关系tcmalloc当一个object free的时候,会根据地址对齐计算所在的页面号,然后通过central array找到对应的span。tcmalloc如果是小对象,span会告诉我们他的size class,然后把该对象插入当前线程的ThreadCache中。如果此时ThreadCache超过一个预算的值(默认2MB),则会使用垃圾回收机制把未使用的object从ThreadCache移动到CentralCache的central free lists中。tcmalloc如果是大对象,span会告诉我们对象锁在的页面号范围。假设这个范围是[p,q], 先查找页面p-1和q+1所在的span,如果这些临近的span也是free的,则合并到[p,q]所在的span, 然后把这个span回收到PageHeap中。tcmallocCentralCache的central free lists类似ThreadCache的FreeList,不过它增加了一级结构,先根据size-class关联到spans的集合, 然后是对应span的object链表。如果span的链表中所有object已经free, 则span回收到PageHeap中tcmalloc相比ptmallocThreadCache会阶段性的回收内存到CentralCache里。解决了ptmalloc2中arena之间不能迁移的问题。tcmalloc相比ptmalloctcmalloc占用更少的额外空间。例如,分配N个8字节对象可能要使用大约8N * 1.01字节的空间。即,多用百分之一的空间。 ptmalloc2使用最少8字节描述一个chunk。tcmalloc相比ptmalloc更快。小对象几乎无锁, >32KB的对象从CentralCache中分配使用自旋锁。并且>32KB对象都是页面对齐分配,多线程的时候应尽量避免频繁分配,否则也会造成自旋锁的竞争和页面对齐造成的浪费
jmallocjmalloc与tcmalloc类似,每个线程同样在<32KB的时候无锁使用线程本地cache。jmalloc在64bits系统上使用下面的size-class分类:
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840]
Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB]
Huge: [4 MiB, 8 MiB, 12 MiB, …]jmallocsmall/large对象查找metadata需要常量时间, huge对象通过全局红黑树在对数时间内查找。jmalloc虚拟内存被逻辑上分割成chunks(默认是4MB,1024个4k页),应用线程通过round-robin算法在第一次malloc的时候分配arena, 每个arena都是相互独立的,维护自己的chunks, chunk切割pages到small/large对象。free()的内存总是返回到所属的arena中,而不管是哪个线程调用free()。jmalloc小对象也根据size-class,但是它使用了低地址优先的策略,来降低内存碎片化。jmalloc大概需要2%的额外开销。(tcmalloc 1%, ptmalloc最少8B)jmalloc和tcmalloc类似的线程本地缓存,避免锁的竞争jmalloc相对未使用的页面,优先使用dirty page,提升缓存命中。
参考
深入理解glibc malloc(https://wooyun.js.org/drops/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%20glibc%20malloc.html)Linux内存点滴 用户进程内存空间(https://www.cnblogs.com/muahao/p/5974594.html)Linux下/proc目录简介(https://blog.spoock.com/2019/10/08/proc/)mallopt(3) - Linux man page(https://linux.die.net/man/3/mallopt)glibc wiki(https://sourceware.org/glibc/wiki/MallocInternals)禁用 mmap 和 memory trip 来加速 MPI RMA(https://enigmahuang.me/2018/09/05/MPI_mmap_trim/)kernel-memory(https://hhb584520.github.io/kvm_blog/2017/03/06/kernel-memory.html)TCMalloc : Thread-Caching Malloc(https://github.com/google/tcmalloc/blob/master/docs/design.md)3-level radix tree 基数树(https://zh.wikipedia.org/wiki/%E5%9F%BA%E6%95%B0%E6%A0%91)understanding-glibc-malloc(https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/)Syscalls used by malloc(https://sploitfun.wordpress.com/2015/02/11/syscalls-used-by-malloc/)几种malloc实现原理 ptmalloc(glibc) && tcmalloc(google) && jemalloc(facebook)(https://msd.misuland.com/pd/300184051069751296)ptmalloc、tcmalloc与jemalloc对比分析(https://www.cyningsun.com/07-07-2018/memory-allocator-contrasts.html#%E8%83%8C%E6%99%AF%E4%BB%8B%E7%BB%8D)内存优化总结:ptmalloc、tcmalloc和jemalloc(http://www.cnhalo.net/2016/06/13/memory-optimize/)