过程状态
TCP 包传输过程
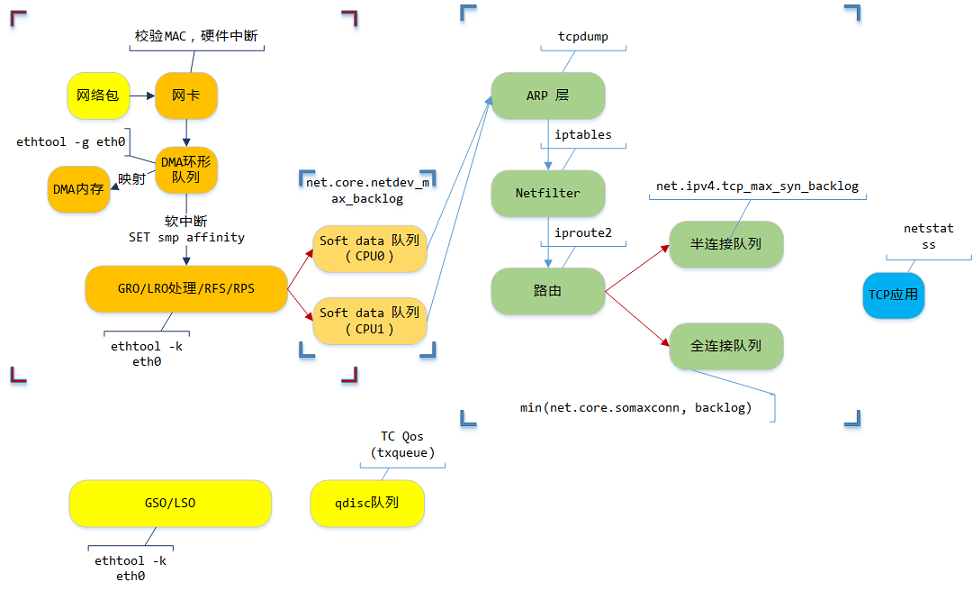
stack
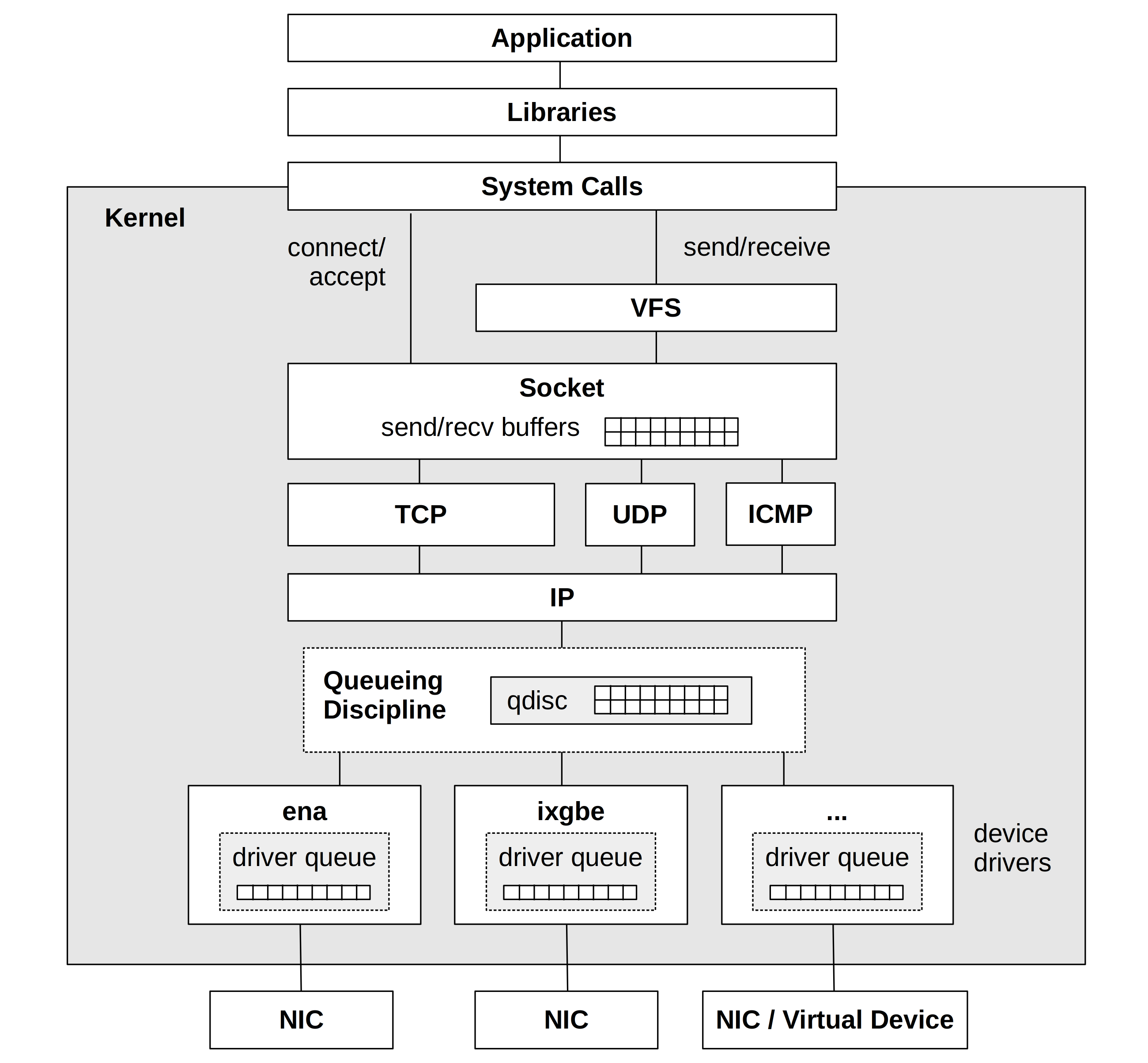
主过程是接收过程
下面两个黄色的
GSO/LSO-> 替换GRO/LRO/RFS/RPS,qdisc队列-> 替换Soft data 队列就是大概的发送过程了图示主要是应用层使用者常见的一些内容,实际网络上的设备、处理要更多
一些说明
DMA: 数据从网卡硬件拷贝到内存GRO/LRO: 数据在网络上是按照mtu值拆分的,如果一个数据包超过了mtu值,那么会被GSO/TSO(也就是下面发送过程替换的块)拆分成多个数据包,接收层GRO/LRO就是讲多个数据包聚合成一个大的数据包的过程- 网卡配置:
ethtool -k eth01
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51Features for eth0:
rx-checksumming: on
tx-checksumming: on
tx-checksum-ipv4: off [fixed]
tx-checksum-ip-generic: on
tx-checksum-ipv6: off [fixed]
tx-checksum-fcoe-crc: off [fixed]
tx-checksum-sctp: off [fixed]
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: off [fixed]
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: off [fixed]
tx-tcp6-segmentation: on
tx-tcp-mangleid-segmentation: off
udp-fragmentation-offload: off [fixed]
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: on
rx-vlan-offload: on
tx-vlan-offload: on
ntuple-filters: off [fixed]
receive-hashing: on
highdma: on
rx-vlan-filter: on [fixed]
vlan-challenged: off [fixed]
tx-lockless: off [fixed]
netns-local: off [fixed]
tx-gso-robust: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-ipip-segmentation: off [fixed]
tx-sit-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
fcoe-mtu: off [fixed]
tx-nocache-copy: off
loopback: off [fixed]
rx-fcs: off [fixed]
rx-all: off [fixed]
tx-vlan-stag-hw-insert: off [fixed]
rx-vlan-stag-hw-parse: off [fixed]
rx-vlan-stag-filter: off [fixed]
busy-poll: off [fixed]
tx-gre-csum-segmentation: off [fixed]
tx-udp_tnl-csum-segmentation: off [fixed]
tx-gso-partial: off [fixed]
tx-sctp-segmentation: off [fixed]
l2-fwd-offload: off [fixed]
hw-tc-offload: off [fixed]
rx-udp_tunnel-port-offload: off [fixed] - 这里面主要关注的一些offload参数:
是一种TCP加速技术,使用于网卡(NIC),将TCP/IP堆疉工作的负载移转到网卡上,用硬件来完成。这个功能常见于高速以太网接口上,如吉比特以太网(GbE)或10吉比特以太网(10GbE),在这些接口上,处理TCP/IP数据包表头的工作变得较为沉重,由网卡硬件进行可以减轻CPU的负担。(https://en.wikipedia.org/wiki/TCP_offload_engine) - 网卡 ring buffer:
ethtool -g eth0
- 网卡配置:
RFS/RPS: 简单理解为多核时代,均衡CPU负载ARP: 地址解析协议qdisc队列(发包过程): 缓存数据包的地方,可以看到这里是可以做流量控制的,收包是没有这一块的,所以说流量控制控制的是发送而不是接收,而网络上有很多网络设备,比如A->B->C,前一个设备是后一个设备的发送方,限速在任意中间设备上做就可以影响最后的下载速度
再下面就是最常接触到的过程了
TC 工具常用
tc qdisc show dev eth0查看当前策略tc qdisc add dev eth0 root netem delay 100ms这个是对网卡eth0 添加策略, 发送的数据包 延时100mstc qdisc add dev eth0 root netem delay 120ms 10ms该命令将 eth0 网卡的传输设置为延迟 120ms ± 10ms (90 ~ 130 ms 之间的任意值)发送。tc qdisc add dev eth0 root netem loss 20% 40%该命令将 eth0 网卡的传输设置为随机丢掉 20% 的数据包,成功率为 40%tc qdisc del dev eth0 root删除所有策略
其他工具:google tcp packet drill (https://github.com/google/packetdrill)
https://cloud.tencent.com/developer/article/1745583
TCP/IP 封装
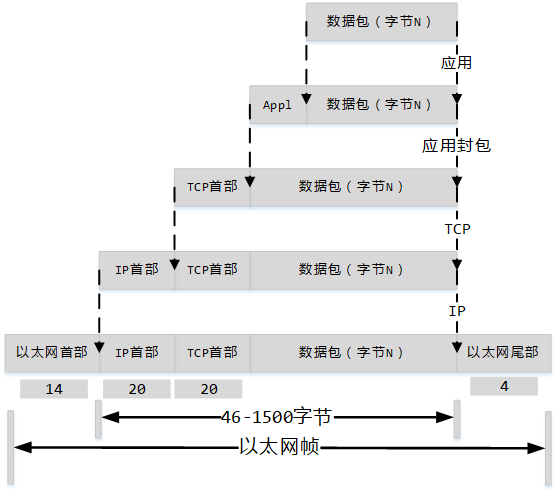
- Appl: 我常用的方式是
message_length(4-byte) + message_id(4-byte) - 为什么包大小是
46-15001500: 经常见到,mtu值46:涉及一个概念,以太网时隙(wiki) 看到这个值最小是512-bit,也就是64-bytes,64-14-4=46
- MTU:IP层的控制,其实这个值可以很大了,但是路径上的最小值才是决定因素,所以一般还是认为这个值是1500
- MSS: TCP层的控制,这个值应 小于等于 MTU,试想一下,如果MSS大于MTU,IP层因MTU拆了包分别是[1,2],这时候IP层会给这两个包都加上IP-header,但是2这时候就没有TCP报文头了
TCP 状态
行为->状态
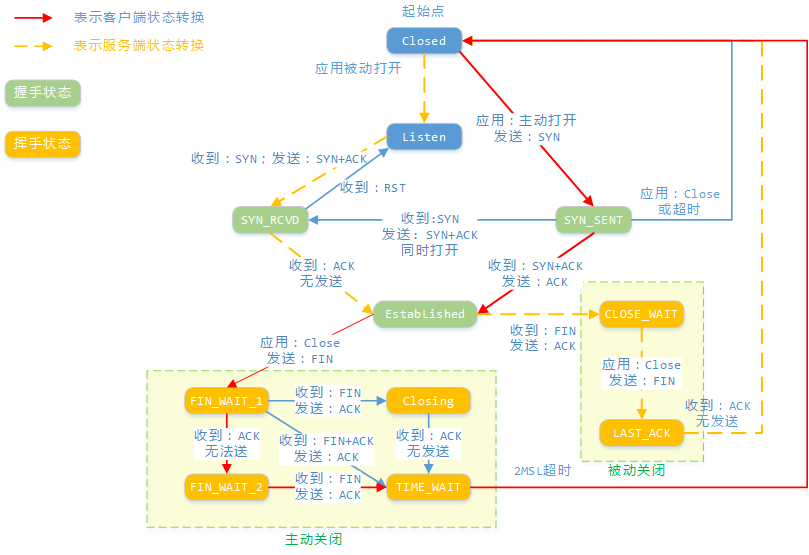
wiki: https://en.wikipedia.org/wiki/File:Tcp_state_diagram_fixed_new.svg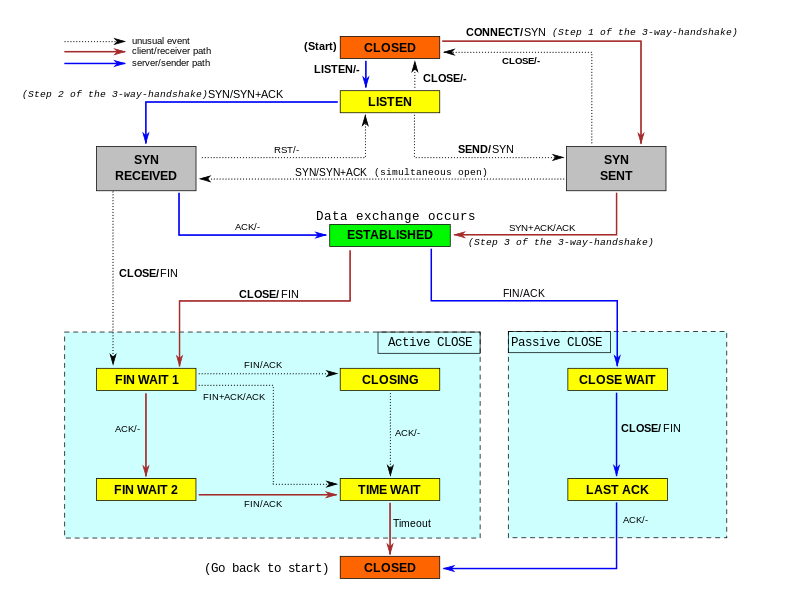
握手->挥手
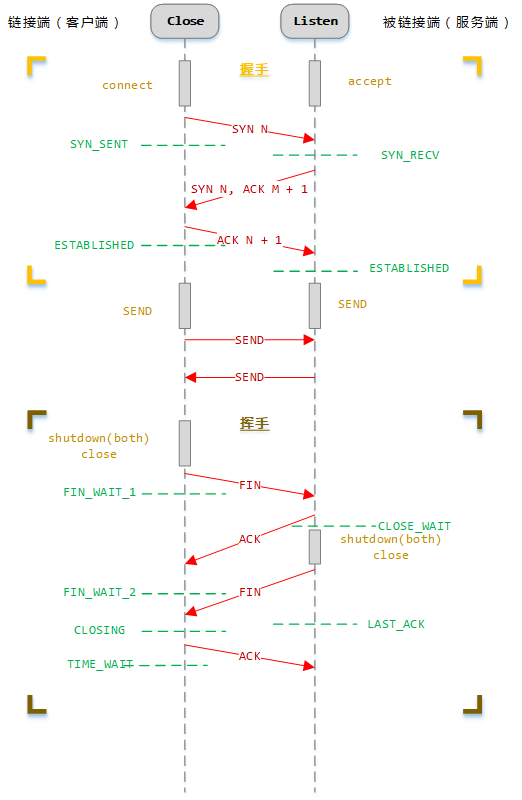
从状态讲起
CLOSE: TCP 未打开或者是关闭的LISTEN: 监听端口打开SYN_SENT: 三次握手,发送SYN报文,然后状态进入SYN_SENT,等待 SYN_ACK,如果请求链接的一方有防火墙限制,会看到这个状态- 如果一定时间没有收到SYN_ACK,会重发SYN包,重发次数由
/proc/sys/net/ipv4/tcp_syn_retries控制(默认5) - 重传的时间间隔:1s,2s,4s,8s,16s;然后等32s,总时长约1分钟
- 如果一定时间没有收到SYN_ACK,会重发SYN包,重发次数由
SYN_RCVD: 对应 SYN_SENT, 收到SYN报文进入这个状态,等待第三次握手报文- 这里的链接被存储在
半连接队列,常见的SYN攻击就是攻击的这个队列,如果这个队列满了,就不能再进来新的连接请求了 netstat -s | grep 'SYNs to LISTEN dropped'查看因半连接队列满造成的丢弃次数;累积值,需要定时轮询统计分析/proc/sys/net/ipv4/tcp_max_syn_backlog- 一定时间没有收到最后一次握手
ACK报文,也会重发SYN_ACK,次数由/proc/sys/net/ipv4/tcp_syn_retries控制(默认5) - 重传时间间隔同上
- 收到
ACK,进到全连接队列并通知到应用的accept,如果应用处理的慢,也会造成全连接队列满 - 全连接队列:
min(/proc/sys/net/core/somaxconn, backlog); 这里的backlog是程序listen的入参 - 如果队列因为一些原因满了,为了更快响应 可以设置
/proc/sys/net/ipv4/tcp_abort_on_overflow= 1,这样就会直接回个RST,避免客户端一直等待;这个值默认是0,因为如果是瞬间上来的量,服务端很有可能再SYN重试的时间内就腾出了accept队列空间,这时候客户端表现是连接时间比较长而已,但是收到RST就要重建连接了 netstat -s | grep 'socket overflowed'查看因accept队列满造成的丢弃次数;累计值,需要定时轮询统计分析
- 这里的链接被存储在
ESTABLISHED:连接成功的状态,可用来过滤统计有效连接数- 到达这个状态就可以互发消息了
- 打开时间戳功能,
/proc/sys/net/ipv4/tcp_timestamps在TCP报文传输的时候会带上发送报文的时间戳,解决序列号绕回造成的关闭一定需要等待的问题 netstat -s | grep 'timestamp'统计因timestamp校验错误导致包被拒绝的数量- 窗口扩大因子
/proc/sys/net/ipv4/tcp_window_scaling,窗口内的数据可以并行发送,窗口可扩大也就意味着两端传输可以提升发送速度 - 发送缓冲区范围
/proc/sys/net/ipv4/tcp_wmem一共三个值,分别是最小值,默认值,最大值 byte - 接收缓冲区范围
/proc/sys/net/ipv4/tcp_rmem一共三个值,分别是最小值,默认值,最大值 byte - 内存范围
/proc/sys/net/ipv4/tcp_mem一共三个值,分别是最小值,默认值,最大值!! 单位是页(4K一页) !! - !!这里遗漏了一些东西(超时重传、快速重传、滑动窗口、MSS),太多了而且机制很有意思,在下面说明
FIN_WAIT_1: ESTABLISHED 状态,发送FIN报文请求关闭连接,并进入这个状态,一般很难见到- 这里一样有重传次数控制:
/proc/sys/net/ipv4/tcp_orphan_retries默认是0(特指8次);可以看出,挥手要求比握手高,超过这个次数,就直接RST了 - 这里也有一个FIN状态连接上限控制:
/proc/sys/net/ipv4/tcp_max_orphans;超过这个上限的,就直接RST了 - 还有一个超时控制:
/proc/sys/net/ipv4/tcp_fin_timeout;默认60s,同样超过了就直接RST
- 这里一样有重传次数控制:
FIN_WAIT_2: FIN_WAIT_1 后收到 ACK 报文,进入这个状态,一般也很难见到- 相关详细内容参考
FIN_WAIT_1
- 相关详细内容参考
CLOSING: 如果是两端同时关闭,都发送了FIN,也收到了对方的FIN,但是还没有收到FIN的ACK,就会到这个状态,一般很难见到TIME_WAIT: 主动关闭的一方才有的状态,连接经历2个MSL(wiki),关闭这个链接,一般会设置成60s*2- 避免延迟的数据段被相同的4元组连接收到
- 等待被动关闭的那边收到完整的关闭消息
- 调整数量限制:
/proc/sys/net/ipv4/tcp_max_tw_buckets - 复用TIME_WAIT状态资源:
/proc/sys/net/ipv4/tcp_tw_reuse, 注意SocketOptions.ReuseAddress是针对绑定端口的,可以绑定TIME_WAIT的端口 - 快速回收TIME_WAIT状态socket:
/proc/sys/net/ipv4/tcp_tw_recycle但是不推荐启用:https://vincent.bernat.ch/en/blog/2014-tcp-time-wait-state-linux -> 中文: https://www.cnblogs.com/sunsky303/p/12818009.html 2022-06-27关于tcp_tw_recycle补充:linux kernel 4.12 (centos 8+ kernel 一般是 4.18), linux 移除了tcp_tw_recycle选项 commit -> 实际代码注释掉了tcp_tw_recycle == 1的处理逻辑,每个新链接都在原基础上增加了 tcp timestamp 的 offsets 值 commit,在这个更新里面看到的是把原来的 tcp_time_stamp 换成了 tcp_time_stamp + tcp_rsk(req)->ts_off; ts_off 的初始化在 af_ops->init_seq(skb, &tcp_rsk(req)->ts_off); 对于IPV4,对应的是 static u32 tcp_v4_init_sequence(const struct sk_buff *skb, u32 *tsoff);而这个函数里面的写法是 hash[1] = (__force u32)daddr; *tsoff = hash[1]; 增加了偏移避免timestamp的单调递增
CLOSE_WAIT: SOCKET 等待应用层主动调用close关闭SOCKET,因为网络层关闭了,上层应用需要处理自己的东西,比如缓冲区、句柄等等,如果netstat看到大量这种状态,基本确定是程序出问题了LAST_ACK:等待挥手最后一个ACK- 上面这些状态(除了
CLOSE)都是占用着系统资源句柄的!! RST: 特殊的响应,暴力关闭、拒绝(不必挥手了,直接释放资源)- 未监听的端口访问
- 不请自来的SYN/ACK/FIN
- 处于 orphan 的socket
- close()
SO_LINGER- l_onoff非0,l_linger为0,close()强制关闭(RST,ACK)
- l_onoff非0,l_linger非0,close() 优雅关闭(FIN)
- tcp_abort_on_overflow
- connect_timeout
- keepalive 超时
TCP 可靠传输
TCP 数据包结构
wiki: https://zh.wikipedia.org/wiki/%E4%BC%A0%E8%BE%93%E6%8E%A7%E5%88%B6%E5%8D%8F%E8%AE%AE
wiki: https://en.wikipedia.org/wiki/Transmission_Control_Protocol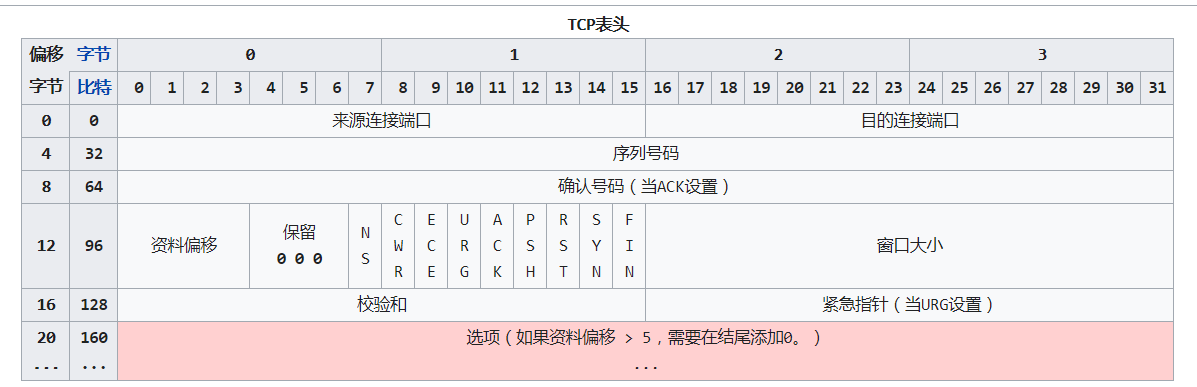

超时重传
- 保证可靠传输中最重要的机制,发送一条消息的时候设置一个定时器,定时器时间内如果没有收到对方的ACK确认包,就重发这条消息
- 超时重传RTO: 超时重传的时间(上面那个定时器用的时间)
- 这个时间多少是最合适的? (https://www.ietf.org/rfc/rfc6298.txt)
- RTT: round-trip time. 往返时间:同一个包来回的时间(以毫秒为单位)
- SRTT: smoothed round-trip time. 平滑的RTT,在数学上使用之前的RTT时间计算出来的时间
- RTTVAR: round-trip time variation
首次计算RTO: (这里的R是第一次测量的RTT,没有RTT的时候 RTO <- TCP_TIMEOUT_INIT 1s)1
2
3
4SRTT <- R
RTTVAR <- R/2
RTO <- SRTT + max (G, K*RTTVAR)
where K = 4. G是clock granularity 时钟粒度,避免K*RTTVAR=0 (一般是100ms) https://stackoverflow.com/questions/12480486/how-to-check-hz-in-the-terminal后续1
2
3
4
5
6
7
8
9
10
11
12
13RTTVAR <- (1 - beta) * RTTVAR + beta * |SRTT - R'|
SRTT <- (1 - alpha) * SRTT + alpha * R'
The value of SRTT used in the update to RTTVAR is its value
before updating SRTT itself using the second assignment. That
is, updating RTTVAR and SRTT MUST be computed in the above
order.
The above SHOULD be computed using alpha=1/8 and beta=1/4 (as
suggested in [JK88]).
After the computation, a host MUST update
RTO <- SRTT + max (G, K*RTTVAR)Whenever RTO is computed, if it is less than 1 second, then the RTO SHOULD be rounded up to 1 second.A maximum value MAY be placed on RTO provided it is at least 60 seconds.- rfc6298
5. Managing the RTO Timer- 5.1. 发送一个带有数据的包后(包括重传),如果RTO定时器未启动,启动RTO定时器
- 5.2. 在确认所有未完成的数据后,关闭RTO定时器
- 5.3. 当收到确认新数据的ACK时,重新设置RTO时间为当前RTO值,然后重启定时器
如果RTO超时了 - 5.4. 接收器尚未确认的最早段
- 5.5. RTO <- RTO * 2 (“back off the timer”,指数回避策略)
- 5.6. 重现设定RTO时间为当前RTO值
- 5.7. 如果握手超时,并且RTO小于3s,连接后初始RTO使用3s (TCP_TIMEOUT_INIT, TCP_TIMEOUT_FALLBACK)
- 超时重传次数:
/proc/sys/net/ipv4/tcp_retries1&/proc/sys/net/ipv4/tcp_retries2两个值控制,其中1之后会做一次路由更新 - 额外:KCP(https://github.com/skywind3000/kcp) 里面提到的和TCP重要的区别,RTO只是1.5,这是一种UDP常用的超发策略,TCP认为超时的情况是网络拥堵了,发的越多会导致网络越来越差(堵)
快速重传
- 另外的重传机制,前面RTO是定时器,这个是依照数据
- 首先,发送数据不可能是发送一次等一个ACK,这样太慢了,是发送N个包,有N个RTO定时器,这N个包在IP层很可能不是有序到达对端的,特别是
ECMP的等价多路径连路上https://www.ietf.org/rfc/rfc3782.txt1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23NewReno算法处理步骤:
1) 三个重复的ACK确认
第3个重复的ACK确认到达而且发送方未进入快速恢复处理时,检查累计的确认值是否大于recover变量, 是则转步骤1A,否则转1B:
1A) 调用快速重传:
设置慢启动阈值(slow start threshold, ssthresh)为:
ssthresh = max (FlightSize / 2, 2*smss)
其中FlightSize表示已经发送但还没有被确认的数据量
然后将发送在最大序列号值保存在recover变量中,转步骤2;
1B) 不调用快速重传:
不进入快速重传和快速恢复处理,不改变ssthresh,不用执行步骤2,3
2) 进入快速重传
重传丢失的包然后设置拥塞窗口CWnd=ssthresh + 3*SMSS,扩大拥塞窗口;
3) 快速恢复
在快速恢复阶段,对于所接收到的每个重复的ACK包,拥塞窗口递增SMSS,扩大拥塞窗口;
4) 快速恢复继续
发送一个数据段,如果新的cwnd和接收端的通知窗口的值允许的话
5) 当一个确认新数据的ACK到达时,此ACK可能是由步骤2中的重传引发的确认,或者是由稍后的一次重传引起的,分完整确认和部分确认两种情况:
完整确认:
此ACK确认了所有数据的序列号括了recover记录的序列号,则此ACK确认了所有中间丢失的数据包,此时调整cwnd或者为(1) min(ssthresh, FlightSize + SMSS);或者(2) ssthresh 来缩小cwnd,结束快速恢复。
部分确认:
如果这个ACK不确认所有并包含到“recover”的数据的话,就产生一个部分ACK。在此种情况下,重传第一个没有确认的数据段。按确认的新数据量来减小拥塞窗口,如果这个部分确认确认了至少一个MSS的新数据,则加回一个MSS。如果cwnd的新值允许的话,发送一个新数据段。这个“部分窗口缩减”试图确定当快速恢复最终结束时,大约ssthresh数量的数据还在向网络中传送。此情况下不退出快速恢复过程。对在快速恢复期间第一个到达的部分ACK,也要重设重传定时器。
6) 重传超时
重传超时后,将发送的最大序列号保存在recover变量中,结束快速恢复过程。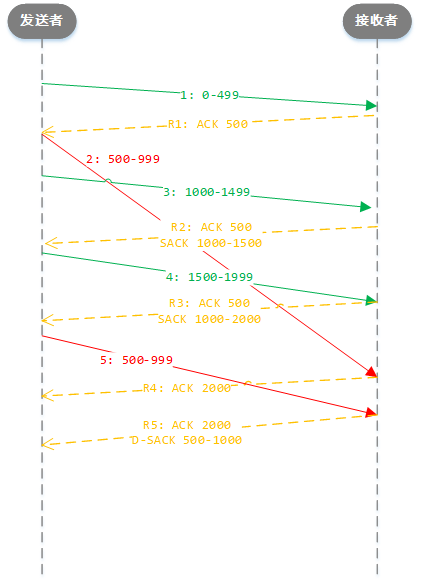
- 这张图上
假设接收方收到包的顺序=发送方发送的顺序假设发送方发送了第2个包2: 500-999在 第4个包到达之后才到达假设开启了SACK功能- 发送方收到R3回执的时候,ACK 500 这个信息收到了3次,触发快速重传,发送第5步
- 这时候接收方收到了前面第2步的包,回执R4: ACK 2000 (没有了SACK信息,因为没有空洞数据了)
- 然后又收到了第5步的数据,说明但是数据重复了,就回了一个R5: 带D-SACK信息的包告诉发送方重复发送了
- SACK:
/proc/sys/net/ipv4/tcp_sack - D-SACK:
/proc/sys/net/ipv4/tcp_dsack
流量控制-滑动窗口
- wiki: https://en.wikipedia.org/wiki/Sliding_window_protocol
- 控制发送者的发送速度,让接收者来得及接收数据,避免接收不过来导致数据丢失
- 前面说到
首先,发送数据不可能是发送一次等一个ACK,这样太慢了,是发送N个包,有N个RTO定时器,这N个包在IP层很可能不是有序到达对端的,特别是ECMP的等价多路径连路上 - 这个N个包也是有限制的,这个限制就是滑动窗口
- 滑动窗口大小是以字节为单位的,TCP报文里面的WIN就是窗口大小(16位=2字节=65535),TCP作为双工模式,这个窗口大小也是两种,
接收窗口大小、发送窗口大小 - 双方相互告知自己的接收窗口大小,
- 接收窗口大小意义:发送数据的时候不能超过另一方的接收窗口大小,不然接收的那一方就无法正常接收到数据了
- 发送窗口大小意义:发送N多的数据,没有及时拿到ACK的话就会导致可用窗口越来越小,到0的时候就不再发送数据了
- 可以看出来,窗口大小是会影响发送速度的
- 只有2字节表示窗口大小显然不够,TCP报文的选项里定义了窗口扩大因子WINDOW SCALING
1
2
3
4
5
6
7For more efficient use of high-bandwidth networks, a larger TCP window size may be used. The TCP window size field controls the flow of data and its value is limited to between 2 and 65,535 bytes.
Since the size field cannot be expanded, a scaling factor is used. The TCP window scale option, as defined in RFC 1323, is an option used to increase the maximum window size from 65,535 bytes to 1 gigabyte. Scaling up to larger window sizes is a part of what is necessary for TCP tuning.
The window scale option is used only during the TCP 3-way handshake. The window scale value represents the number of bits to left-shift the 16-bit window size field. The window scale value can be set from 0 (no shift) to 14 for each direction independently. Both sides must send the option in their SYN segments to enable window scaling in either direction.
Some routers and packet firewalls rewrite the window scaling factor during a transmission. This causes sending and receiving sides to assume different TCP window sizes. The result is non-stable traffic that may be very slow. The problem is visible on some sites behind a defective router.[24] - 滑动窗口分为4部分:图片来自(https://www.cnblogs.com/xiaolincoding/p/12732052.html)
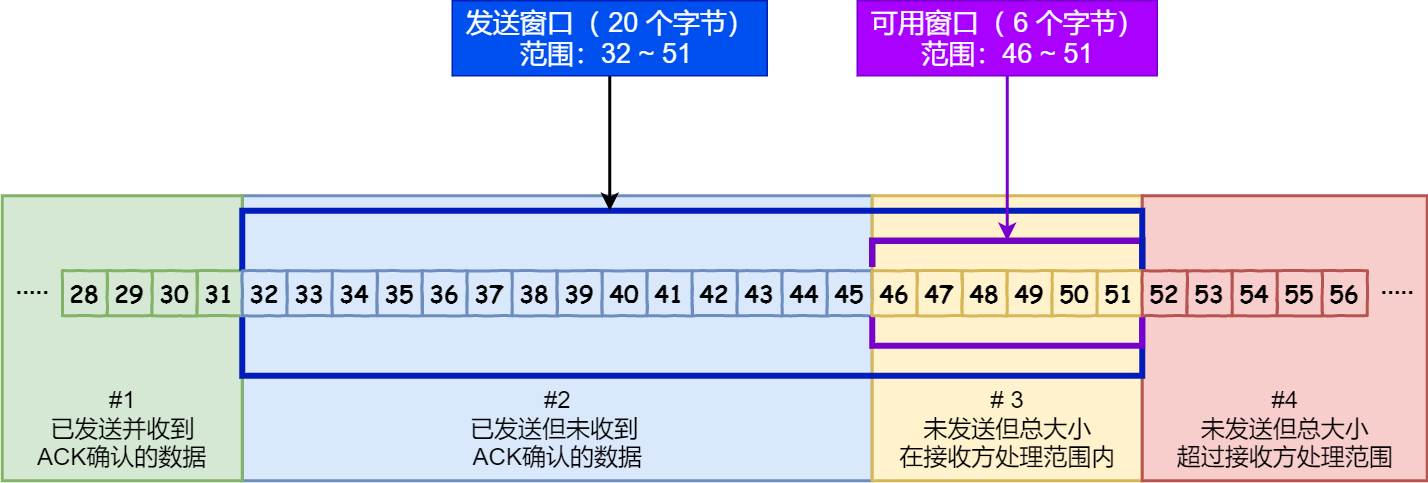
- #1. 已经收到ACK确认的数据
- #2. 已经发送但是还没有收到ACK确认的数据
- #3. 在窗口大小内,还没有发送的数据
- #4. 窗口外的数据
- 额外:前面快速重传+SACK图,发送0-499,ACK: 500,这个500就是告知对方发送的窗口指针可以移到那个位置了
- 发送窗口发送数据的策略:Nagle 延时发送策略 (https://en.wikipedia.org/wiki/Nagle%27s_algorithm)
- #1. 待发送数据大小 >= MSS
- #2. 对方窗口大小 >= MSS
- #3. FIN 包
- #4. TCP_NODELAY
- #5. 收到了之前发送数据的确认包
- #6. 200ms timeout
- 延迟确认 (delayed ACKs)
- 确认包很小,默认准备好确认包40ms timeout 发送,如果这期间有其他包需要发送,就把确认包一起带上发送出去
拥塞控制
- wiki (https://en.wikipedia.org/wiki/TCP_congestion_control)
- 流量控制是一个socket通道上的,拥塞控制属于链路上的网络环境,在较差的网络环境上TCP的重传机制会使网络负担越来越重,因此就有了拥塞控制的内容,避免雪崩式拥塞,若出现拥塞而不进行控制,整个网络的负担会随着输入的负荷增大而增大,恶性循环,因此加入拥塞控制机制避免这种情况
概念:拥塞窗口: cwnd 是确定可以随时发送的字节数的因素之一。拥塞窗口由发送方维护,是一种阻止发送方和接收方之间的链接因流量过多而过载的方法。这不应与接收器保持的滑动窗口混淆,该滑动窗口存在以防止接收器过载。通过估算链路上有多少拥塞来计算拥塞窗口。- 建立连接后,拥塞窗口(在每个主机上独立维护的值)将设置为该连接所允许的MSS的很小的倍数。拥塞窗口的进一步变化由加性增加/乘性减少(AIMD)方法决定。这意味着,如果所有段均已接收并且确认已按时到达发送方,则将某些常量添加到窗口大小中。当窗口达到ssthresh时,在收到的每个新确认中,拥塞窗口以1 /(拥塞窗口)段的速率线性增加。窗口不断增长,直到发生超时。超时时:
- #1. 拥塞窗口重设为1 MSS。
- #2. ssthresh设置为超时前拥塞窗口大小的一半。
- #3. 启动慢速启动。
下面将围绕拥塞控制的内容具体说下TCP拥塞控制的算法
- #1. 慢启动
- #2. 拥塞避免
- #3. 拥塞发生(快重传)
- #4. 快恢复
慢启动
- 慢启动简单的说就是刚建立网络连接的时候,一点点的提速,而不是一上来就把通道占满
- 具体的过程:
- #1. 连接建立之初,
cwnd = 1,此时可以传1*MSS大小的数据 - #2. 收到一个确认包
ack,cwnd += 1 - #3. 这时候就可以发送
2*MSS的数据了,接收方会回复2*ack,for(2次) cwnd += 1 - #4. cwnd 的增长呈指数增加 1, 2, 4, 8….
- #5. cwnd 的增长也是有上限的,
cwnd < ssthresh(NewReno算法处理步骤)
- #1. 连接建立之初,
拥塞避免
- 上面慢启动的过程是
cwnd < ssthresh,当cwnd >= ssthresh时候,就到了拥塞避免阶段 - 上面慢启动是一个指数增长,而拥塞避免是线性增长的过程,假设
ssthresh == 8
图片来自(https://www.cnblogs.com/xiaolincoding/p/12732052.html)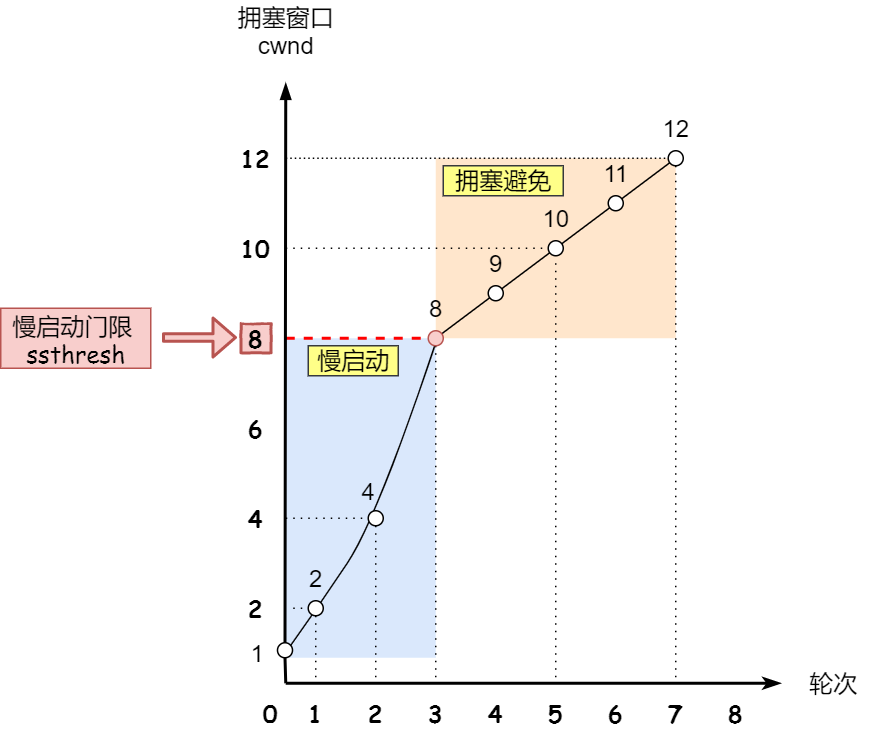
拥塞发生(快重传)
- 拥塞线性增长到达一定值的时候,网络负担会越来越重,这时候就会有包开始因为网络拥塞而重传了
- 这里有两种情况:
- #1. 超时重传(RTO超时没有收到确认包)
ssthresh = cwnd / 2; cwnd = 1;
此时大部分情况cwnd < ssthresh,回到慢启动状态- #2. 快速重传(接收方发现中间少了包,重复发了三次前一个包的ack,触发快速重传)
cwnd = cwnd / 2; ssthresh = cwnd;
此时大部分情况cwnd == ssthresh,回到拥塞避免状态
快速恢复
- 拥塞发生时候,当是快速重传的情况
- #1. 收到了3个重复的ack
- #2.
cwnd = cwnd / 2; ssthresh = cwnd; - #3.
cwnd += 3; - #4. 发送中间丢的数据包
- #5. 收到确认ack,
cwnd += 1; - #6. 基本回到之前的状态了
汇总图
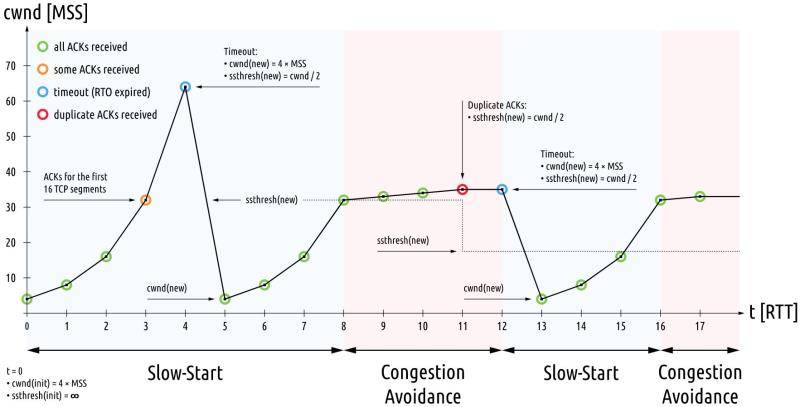
错误控制
- TCP 最常见的错误:(wireshark 经常看到的标记黑色的那些)
- TCP Retransmission (tcp重传:发送端发送的数据接收端一定时间RTO没有收到,就会触发这个错误,发送端将触发重传)
- TCP Fast Retransmission (tcp快速重传:上面是RTO时间,这个是收到了3个重复的ACK确认序号触发的快速重传)
- TCP Dup ACK 数字A#数字B (tcp重复ACK:数字A是重复的序列号,数字B是重复的次数)
- TCP Out-of-order (接收到的顺序错乱:一般是发送端到接收端链路上有多个路径,一条长路径上的晚到了,TCP会做一些工作保证顺序重组)
- TCP window update (窗口更新)
- TCP zerowindow (包种的“win”代表接收窗口的大小,当Wireshark在一个包中发现“win=0”时,就会发提示。)
- TCP window Full (窗口被填满了)
sysctl.conf 调优
1 | kernel.sysrq = 0 |
参考
- https://zh.wikipedia.org/wiki/TCP%E6%8B%A5%E5%A1%9E%E6%8E%A7%E5%88%B6
- https://zh.wikipedia.org/wiki/%E4%BC%A0%E8%BE%93%E6%8E%A7%E5%88%B6%E5%8D%8F%E8%AE%AE
- https://www.cnblogs.com/xiaolincoding/p/12732052.html
- https://en.wikipedia.org/wiki/Transmission_Control_Protocol
- http://www.medianet.kent.edu/techreports/TR2005-07-22-tcp-EFSM.pdf
- https://tonydeng.github.io/sdn-handbook/linux/tc.html
- http://blog.hyfather.com/blog/2013/03/04/ifconfig/
- https://tonydeng.github.io/sdn-handbook/linux/kernel-network-params.html
- https://plantegg.github.io/2019/05/08/%E5%B0%B1%E6%98%AF%E8%A6%81%E4%BD%A0%E6%87%82%E7%BD%91%E7%BB%9C--%E7%BD%91%E7%BB%9C%E5%8C%85%E7%9A%84%E6%B5%81%E8%BD%AC/
- https://access.redhat.com/sites/default/files/attachments/20150325_network_performance_tuning.pdf
- https://blog.csdn.net/dog250/article/details/51439747
- https://www.cnblogs.com/yulia/p/10346339.html
- https://beta.computer-networking.info/syllabus/default/exercises/tcp.html
- https://beta.computer-networking.info/syllabus/default/exercises/tcp-2.html
2022-06-27 更新参考
- https://www.cnblogs.com/brucemengbm/p/7028969.html - tcp_tw_recycle检查tcp_timestamps的内核代码
- https://blog.51cto.com/professor/1909022 - TCP timestamp 相关知识
- https://juejin.cn/post/7094826862970404895 - 我们为什么关掉了 TCP Timestamp